안녕하세요. 바른 호랑이입니다.
이번 게시글에서는 경영정보시각화능력 자격증의 2과목인 데이터 해석 및 활용과 관련된 내용에 대해서 알아볼 예정입니다.
내용은 경영정보시각화능력 필기 수험 가이드북을 기준으로 작성하였으니 참고하시면 되겠습니다.
Section 01 데이터 이해 및 해석
1. 데이터의 이해
1) 데이터의 개념
| 항 목 | 세 부 내 용 |
| 데이터(Data) | 현실 세계에서 단순히 관찰하거나 측정하여 수집한 사실이나 값 의미가 부여되지 않은 객관적 사실 가공하기 전 순수한 수치나 기호 자체 예시: 회원의 가입내역, 대리점의 매출내역, 회원의 시스템 로그인 시간 등 |
| 정보(Information) | 의사결정에 유용하게 활용할 수 있도록 데이터를 처리한 결과물 다양한 정보를 구조화해 유의미한 정보로 분류 데이터 간 상관/연관관계 속에서 의미 부여 유용성은 상황에 따라 다름 예시: 회원의 가입내역을 처리한 회원의 연령별 분포도, 대리점의 매출내역을 처리한 대리점별 평균 매출액, 매출이 많은 베스트 대리점, 회원의 시스템 로그인을 처리한 회원들이 가장 많이 로그인한 시간대 등 |
| 지식(Knowledge) | 정보를 바탕으로 의사결정에 활용하는 것 개인의 경험에 결합해 고유의 지식으로 내재화 각자 자기 관점에서 근거 데이터를 업무에 활용 |
| 통찰(Insight) | 지식의 축적과 아이디어가 결합된 창의적인 사물 근본 원리에 대한 깊은 이해를 바탕으로 도출되는 창의적인 아이디어 |
2) 빅데이터의 개념
① 빅데이터의 3대 요소(3V)
ㆍ규모(Volume): 데이터의 양을 의미하는 것으로 SNS의 데이터 피드, 웹페이지나 모바일 앱의 클릭 스트림, 센서 지원 장비와 같은 RFID를 이용해 수집한 로우 데이터들이 생겨나고 이 크기가 TB이상으로 거대해짐.
ㆍ속도(Velocity): 데이터의 수신 및 처리 속도를 의미하는 것으로, 일반적으로 데이터를 디스크에 기록하는 것보다 메모리로 직접 스트리밍 할 때 속도가 가장 빠름. 일부 인터넷 지원 스마트 제품은 실시간 또는 거의 실시간으로 작동하기 때문에 실시간 평가 및 조치가 필요함.
ㆍ다양성(Variety): 사용 가능한 데이터 유형의 다양성을 의미하는 것으로 기존 데이터 유형은 구조화되어 RDB에 적합한데 반해 텍스트, 오디오 및 비디오 같은 비정형 및 반정형 데이터들의 활용이 중요해짐에 따라 다양한 데이터들한테서 의미를 도출하고 메타데이터를 지원하기 위해 추가로 처리가 필요해지게 되었음.

② 빅데이터의 역사
ㆍ대규모 데이터 세트의 기원은 최초의 데이터 센터 등장, RDB의 개발 등이 시작된 1960~70로 거슬러 올라가며, 2005년 무렵 Facebook, Youtube 등과 같은 기타 온라인 서비스를 통해 사용자가 생성하는 많은 양의 데이터에 대한 인식이 확산되고, Hadoop의 개발과 NoSQL이 인기를 얻으며 본격적으로 발전 가속도가 붙기 시작함.
ㆍIoT(Internet of Things)의 출현으로 더 많은 객체와 장치가 인터넷과 연결되어 고객 사용 패턴 및 제품 성능에 대한 데이터를 수집하고 있으며, 머신러닝의 등장으로 더 많은 데이터가 생성되고 있고, 클라우드 컴퓨팅의 보편화로 인해 빅데이터의 가능성이 더욱 확장되었음.
③ 빅데이터의 사용 사례
ㆍ제품 개발: 고객 수요를 예측 후 테스트 시장, 초기 매장 출시 데이터 및 분석 자료를 토대로 신규 제품을 계획, 생산, 출시할 수 있음.
ㆍ예측적 유지보수: 장비 생산연도, 제조사, 장비 모델과 같은 정형 데이터와 수백만 개의 로그 항목, 센서 데이터, 오류 메시지, 엔진 온도 등 비정형 데이터를 통해 장비 고장을 예측할 수 있으며, 문제 발생 전 잠재적 문제에 대한 징후를 분석함으로써 비용 효율적으로 유지보수를 배치하고 부품 및 가동 시간을 최대화할 수 있음.
ㆍ운영 효율성: 빅데이터를 사용하면 생산, 고객 피드백 및 반품, 기타 요인을 분석하고 평가하여 운영 중단을 줄이고 향후 수요를 예측할 수 있으며, 현재 시장 수요에 따라 운영에 대한 의사결정을 개선하는 데 사용할 수 있음.
ㆍ머신러닝: 빅데이터를 사용해 머신러닝 모델을 훈련하여 여러 분야에 활용할 수 있음.
④ 빅데이터의 작동 원리
ㆍ통합: 빅데이터는 서로 다른 종류의 소스와 애플리케이션으로부터 데이터를 수집하여 종합하며, ETL과 같은 기존의 데이터 통합 메커니즘으로 이와 같은 작업을 모두 수행하기에는 어려움 있기에 TB 또는 PB 규모로 빅데이터 세트를 분석하려면 새로운 전략과 기술이 필요함.
ㆍ관리: 빅데이터를 관리하기 위해 Storage가 필요하며, 스토리지를 활용하여 데이터를 저장하고 처리 요구사항과 필요한 프로세스에 따라 데이터를 변형하는 것이 필요함. 일반적으로 데이터의 상주 위치에 따라 스토리지를 선택함.
ㆍ분석: 다양한 데이터 세트의 시각적 분석을 통해 명확성을 확보할 수 있으며, 새로운 발견을 위해 데이터를 추가로 탐색하는 것이 가능하고, 내용을 타인과 공유할 수 있음. 머신러닝 및 인공지능으로 데이터 모델을 구축하고 데이터를 업무에 활용할 수 있음.
3) 데이터의 종류
① 형태에 따른 데이터 분류
ㆍ정형 데이터: 구조화된 데이터로 엑셀의 스프레드시트, RDB의 테이블등이 이에 해당함.

ㆍ반정형 데이터: 일부 구조를 갖추고는 있으나 정형 데이터처럼 완전하게 구조화되어 있지 않은 데이터들로 보통 Key-Value형태로 이루어져 있고, parsing과정이 필요힘. 보통 파일의 형태로 저장되며 HTML, XML, JSON문서나 웹 로그, 센서 데이터 등이 이에 해당함.

ㆍ비정형 데이터: 정해진 구조가 없이 저장된 데이터로 SNS의 텍스트, 이미지, 영상, PDF 문서와 같은 멀티 미디어 데이터가 대표적이고, SNS 이용률이 크게 높아짐에 따라 실시간으로 많은 양의 비정형 데이터가 생산됨.
② 특성에 따른 데이터 분류

ㆍ범주형 데이터: 범주로 구분할 수 있는 값으로 종류를 나타내는 값을 가진 데이터이며, 크기 비교와 산술적인 연산이 가능하지 않아 질적 데이터라고도 함.
▶ 명목형 데이터(Nominal Data): 순서, 즉 서열이 없는 값을 가지는 데이터로 성별, 혈액형, 학과명, 거주 지역, 음식 메뉴, MBTI 검사 결과 등이 이에 해당함.
▶ 순서형 데이터(Ordinal Data): 순서, 즉 서열이 있는 값을 가지는 데이터로 학년, 학점, 회원등급 등이 이에 해당함.
ㆍ수치형 데이터: 크기 비교와 산술적인 연산이 가능한 숫자 값을 가진 데이터로 양적 데이터라고도 함.
▶ 이산형 데이터(Discrete Data): 개수를 셀 수 있는 띄엄띄엄 단절된 숫자 값을 가지는 데이터로 고객 수, 판매량, 합격자 수 등이 이에 해당함.
▶ 연속형 데이터(Continuous Data): 측정을 통해 얻어지는 연속적으로 이어진 숫자 값을 가지는 데이터로, 키, 몸무게, 온도, 점수 등이 이에 해당함.
2. 데이터의 해석
1) 데이터 해석 관점
① 데이터 해석 관점
ㆍ데이터가 가진 의미와 데이터를 바라보는 관점에 따라 의사결정 결과가 달라질 수 있음.
▶ A화장품 브랜드의 고객의 비중이 20대 여성 60%, 30대 여성 30%, 그 외 집단 10%로 구성되고 매출액 비중은 20대 여성 50%, 30대 여성 30%, 그 외 집단 10%로 구성된 상황을 가정하면, 고객 중 높은 비중을 차지하는 20대 여성의 1인당 구매금액을 높이는 방향과, 1인당 평균 구매금액이 더 큰 30대 여성을 고객으로 확보하는 방향 등 다양하게 해석하는 것이 가능함.
② 데이터 해석 오류
ㆍ데이터 해석 관점에 정답은 없으나 데이터의 정확한 해석을 방해하는 오류에 대한 대처는 필요함
| 오 류 | 세 부 내 용 |
| 거짓 인과관계 (False cause) |
우연히 나타난 현상이나 상관관계만 나타난 현상을 인과관계로 오인하는 것 |
| 생존 편향 (Surviorship bias) |
선택 과정을 통과한 개체의 데이터만 남아 선택 과정을 통과하지 못한 개체의 데이터를 간과하는 논리적 오류로 예시로 서비스에 만족하지 않아 탈퇴한 가입자를 고려하지 않은 만족도 조사가 있음. |
| 심슨의 역설 (Simpson's paradox) |
세부 집단별로는 추세나 경향성이 나타나지만 전체적으로 추세가 사라지거나 반대의 경향성이 나타나는 현상 |
| 체리피킹 (Cherry picking) |
불리한 데이터나 사례는 숨기고 유리한 데이터를 활용하여 주장을 뒷받침하는 것 |
2) 데이터 기초 통계
① 통계
ㆍ특정 집단에 대해 조사나 실험을 통해 얻은 수치를 활용하여 특정 집단을 구성하는 각각의 정보를 하나의 요약된 값으로 표현한 것
② 주요 통계 용어
| 용 어 | 세 부 내 용 |
| 모집단 | 연구와 조사 또는 분석이 이루어지는 집단 관심 대상 전체를 의미 |
| 표본(Sample) | 일반적으로 모집단 전부를 수집하여 분석할 수 없으므로 일부분을 추출하여 분석하는 대상을 의미 |
| 기술통계 | 수집한 데이터를 정리, 요약, 해석 등을 통해 데이터의 특성과 속성을 파악하는 방법 |
| 추론통계 | 표본으로부터 통계량 등의 값을 계산하여 모집단의 특성과 속성을 파악하는 방버 |
| 확률 | 어떤 사건이 실제로 일어날 것인지 혹은 일어났는지에 대한 지식 혹은 믿을 표현하는 방법으로 같은 원인에서 특정한 결과가 나타나는 비율을 뜻하기도 함. |
| 조건부 확률 | 주어진 사건이 일어났다는 가정하에 다른 한 사건이 일어날 확률 |
| 도수분포표 | 데이터가 속하는 항목 또는 특정 범위의 빈도를 나타낸 표 |
| 히스토그램 | 데이터가 속하는 항목 또는 특정 범위의 빈도를 나타낸 그래프 |
| 평균(Mean) | 전체 데이터의 총합을 전체 데이터의 수로 나눈 값 |
| 중앙값(Median) | 전체 데이터를 나열했을 때 가운데에 있는 값으로 데이터가 홀수 개일 경우 가운데 값을 짝수 개일 경우 가운데 두 값의 평균을 사용함 |
| 최빈값(Mode) | 전체 데이터 중 가장 높은 빈도를 보이는 값 |
| 분산(Variance) | 확률변수가 기댓값으로부터 얼마나 떨어진 곳에 분포하는지를 가늠하는 숫자 |
| 표준편차(Standard Deviation) | 분산의 제곱근을 취한 값 |
| 공분산(Convariance) | 두 변수가 각자의 평균으로부터 멀어지는 값 |
| 상관계수(Correlation Coefficient) | 두 변수 사이의 통계적 관계를 표현하기 위해 특정한 상관관계의 정도를 수치로 나타낸 것 |
| 가설검정 | 통계적 추측의 하나로, 가설에 대해 표본의 정보를 이용해 합당성 여부를 판정하는 과정을 의미함 |
3) 확률과 확률분포
① 확률분포
ㆍ확률변수가 특정합 값을 가질 확률을 나타내는 함수(집합 내의 임의의 한 원소를 다른 집합의 한 원소에 대응시키는 관계)로 확률변수의 종류에 따라 이산확률분포와 연속확률분포로 나누어짐.
② 이산확률분포
ㆍ이산확률변수의 확률분포를 의미하며, 확률변수 X를 주사위를 던져서 나오는 눈의 개수라고 하면 X는 6가지 경우를 가질 수 있는데, 이와 같이 확률변수 X가 가질 수 있는 값을 셀 수 있는 경우 이산확률변수라고 지칭함.
ㆍ이산확률분포의 종류
▶ 베르누이분포: 결과가 두 가지 중 하나로만 나오는 시행(베르누이 시행)이 나타내는 확률분포
▶ 이항분포: N번의 독립적인 베르누이시행 중 성공횟수의 확률분포로, 베르누이분포는 이항분포의 시행 횟수가 1인 경우에 해당.
▶ 기하분포: 성공확률이 p인 베르누이시행에서 처음 성공이 일어날 때까지 반복한 시행횟수의 확률분포
▶ 음이항분포: 성공확률이 p인 베르누이시행을 r번 성공할 때까지 반복시행한 횟수의 확률분포로, 기하분포는 성공 횟수 r=1인 음이항분포에 해당함.
▶초기하분포: N개 중 비복원추출로 n번 추출했을 때 원하는 것이 k개 포함될 확률의 분포
▶포아송(Poisson)분포: 단위 시간 내에 어떤 사건이 발생하는 횟수를 나타내는 분포
③ 연속확률변수
ㆍ연속확률변수의 확률변수를 의미하며, 확률변수 Y를 중학교 1학년 학생의 평균 키라고 했을 때, Y는 실수 값을 가지는데, 이와 같이 확률변수 Y가 셀 수 없는 값을 가지는 경우 연속확률변수라고 지칭함.
ㆍ연속확률분포의 종류
▶ 정규분포: 중심극한정리(확률분포를 알 수 없는 어떠한 변수라도 정해진 횟수 n만큼 독립적으로 추출하는 작업을 반복했을 때 추출된 값의 평균은 n이 커짐에 따라 정규분포에 근접함.)에 따라 동일한 분포를 가지는 많은 확률변수의 평균 분포를 근사할 수 있는 분포
▶ 감마분포: a번째 사건이 일어날 때까지 걸리는 시간에 대한 연속확률분포
▶ 지수분포: 사건이 서로 독립적일 때 사건과 사건 간의 경과시간에 대한 확률분포
▶ 카이제곱분포: k개의 서로 독립적인 표준정규확률변수의 제곱을 합한 값에서 얻어지는 분포
▶ 베타분포: 두 매개변수 α와 β에 따라 [0, 1] 구간에서 정의되는 연속확률분포
▶ 균등분포(균일분포): 특정구간 내의 값들이 나타날 가능성이 균등한 분포
4) 데이터 마이닝
① 데이터 마이닝
ㆍ데이터베이스나 데이터웨어하우스 등에 저장된 방대한 데이터로부터 의사결정에 도움이 되는 유용한 정보를 발견하는 일련의 작업으로 고객 마케팅 및 신용평가, 품질관리, 이미지 분석 등 다양한 분야에 활용됨.
② 데이터 마이닝의 특징
ㆍ대용량의 관측 가능한 자료를 다루고, 관측자료는 시간의 흐름에 따라 비계획적으로 축적되며, 자료분석을 염두에 두고 수집되지 않음.
ㆍ컴퓨터 중심적인 기법으로 수리적으로 밝혀지지 않는 경험적 방법에 근거하며, 일반화에 초점을 맞추고, 경쟁력 확보를 위한 의사결정을 지원하기 위해 활용됨.
③ 데이터 마이닝의 분석 기술
ㆍ연관분석: 대규모 데이터 항목 중 유용한 연관성과 상관관계를 찾는 기법으로 상품 또는 서비스 간의 관계로부터 유용한 규칙을 찾아내고자 할 때 이용함.
▶ 함께 구매하는 상품의 조합이나 서비스 패턴을 발견하고자 할 때 많이 사용하여 장바구니 분석이라고도 하며, "감자칩을 구입하는 고객의 30%는 맥주도 함께 구입한다."와 같은 연관성을 분석함.
ㆍ군집분석: 집단 또는 범주에 대한 사전 정보가 없는 데이터에 대해 전체를 몇 개의 유사한 집단으로 그룹화하여 각 집단의 성격을 파악하는 기법
▶ 모집단을 미리 정의되어 있지 않은 부분집합으로 분류하는 것이며, 그룹화가 끝난 후에야 그룹의 특성을 파악할 수 있음.
▶ 각 개체간의 유사도를 측정하기 위해 거리함수를 사용하여 군집분석을 시행하며, 계층적인 방법으로는 K-means 군집분석이 있고, 비계층적 방법으로는 병합적인 방법, 분할적인 방법이 있음.

ㆍ분류분석
▶ 대표적인 분류분석 기법으로는 의사결정나무 기법이 있으며 사전에 결과를 알고 있는 데이터를 가지고 지도학습을 진행한 이후 특정값들의 결괏값을 예측하는 방법임.
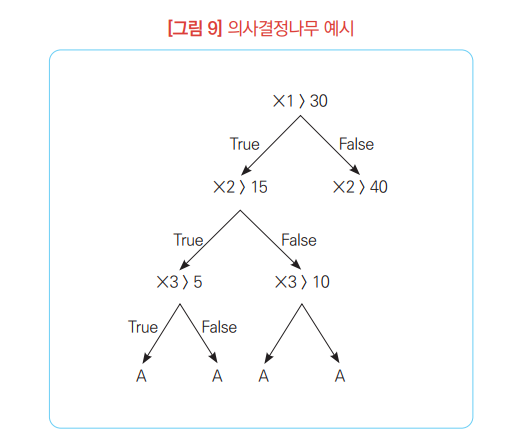
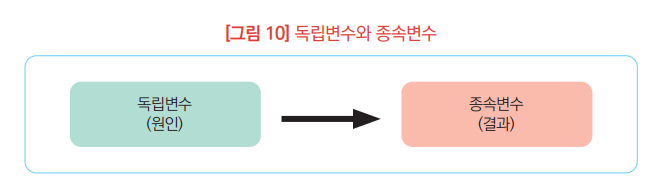
ㆍ회귀분석(Regression Analysis)
▶ 변수 간의 함수관계를 추구하는 통계적인 방법으로 독립변수(Independent Variable, 입력값이나 원인으로 explanatory variable이라고도 함.)와 종속변수(Dependent Variable, 결과물이나 효과로 responsive variable이라고도 함.) 간의 함수관계를 규명하는 통계적인 방법임.
Section 02 데이터파일시스템
1. 데이터파일시스템의 개념 및 종류
1) 자료의 계층구조
① 개요
ㆍ파일시스템은 자료의 계층구조를 가지고 있어 데이터를 효율적으로 저장하고 검색할 수 있음.
② 블록(Block)
ㆍ파일시스템의 가장 낮은 계층으로 일정한 크기의 데이터 조각으로 파일시스템에 저장되고, 각 블록은 고유한 주소를 가진 상태로 파일시스템은 이와 같은 블록들을 조직화하여 파일이나 폴더에 할당함.
③ 파일(File)
ㆍ사용자가 생성하는 데이터의 단위로 파일은 블록들의 집합으로 구성되며, 각 파일은 파일시스템에서 고유한 식별자(파일명 혹슨 파일 경로)를 가짐.
ㆍ파일은 데이터와 파일에 대한 메타데이터(파일 크기, 생성 일자, 수정 일자 등)를 포함하고, 파일시스템은 파일의 데이터를 여러 개의 블록에 분산하여 저장하고, 파일의 메타데이터는 특정 블록에 저장되거나 파일시스템의 다른 영역에 저장될 수 있음.
④ 디렉토리(Directory)
ㆍ파일이나 다른 디렉터리를 포함할 수 있는 컨테이너 역할을 수행하며, 파일을 조직화하기 위한 계층구조를 제공함.
ㆍ파일시스템에서 각 디렉터리는 고유한 식별자인 디렉토리 경로를 가지며, 사용자는 디렉터리를 통해 파일에 쉽게 접근할 수 있음.
ㆍ파일시스템 내에서 파일의 계층구조를 형성하며, 파일과 다른 하위 디렉토리를 포함할 수 있음.
2) 데이터파일시스템의 개념
① 데이터파일시스템
ㆍ데이터파일시스템은 파일시스템과 데이터베이스관리시스템을 통칭함.
② 파일시스템
ㆍ파일과 폴더를 저장, 관리, 접근하는 체계로서, 자료의 계층구조를 통해서 데이터를 구조화하고 조직화함.
ㆍ데이터를 논리적으로 구성하고 저장 장치에 효율적으로 배치하여 파일의 생성, 수정, 삭제, 검색 등의 작업을 수행하도록 하고 HHD, SSD, 네트워크 드라이브 등의 저장 장치에 적용됨.
ㆍ파일, 폴더, 디렉토리를 통해 자료의 계층구조를 구현하고, 폴더에 대한 접근 권한도 관리하며, 읽기, 쓰기, 실행 등의 권한을 할당하여 데이터의 보안을 유지함. 이를 통해 승인받지 않은 액세스를 방지하고 데이터를 안전하고 보관할 수 있음.
③ 데이터베이스관리시스템(DBMS, DataBase Management System)
ㆍ 파일시스템의 단점을 극복하기 위해 등장한 개념으로 DB에 접근하여 DB의 정의, 조작, 제어 등의 관리를 지원하는 소프트웨어를 의미함.
3) 데이터파일시스템의 종류 및 특성
⑴ 파일시스템의 종류 및 특성
① 파일시스템의 종류
ㆍFAT32, NTFS, ext4, APFS, HFS+등이 있으며 각 OS와 저장 장치에 맞게 최적화되어 발전해 왔음.
② 특징
| 항 목 | 세 부 내 용 |
| 조직화된 데이터 저장 | 파일시스템은 데이터를 조직화하여 저장하며, 파일의 크기에 맞게 데이터를 블록 단위로 나누어 저장하고, 각 파일에 대한 메타데이터를 관리함. 조직화된 저장 방식 덕분에 데이터의 효율적인 관리와 검색이 가능함. |
| 계층구조 | 파일시스템은 파일과 폴더의 계층구조를 제공하며, 폴더는 파일을 그룹화하고 조직화하는 데 사용됨. |
| 파일 및 폴더의 식별자 | 각 파일과 폴더를 고유한 식별자로 식별하여 파일에 접근할 수 있음. |
| 접근 권한 관리 | 파일과 폴더에 대한 접근 권한을 관리함. |
| 백업과 복구 | 데이터의 백업과 복구를 지원함. |
③ 단점
| 항 목 | 세 부 내 용 |
| 데이터 중복 및 일관성 문제 | 여러 파일에 동일한 데이터를 중복해서 저장하는 경우 데이터의 일관성이 깨질 수 있음. |
| 데이터 무결성 유지의 어려움 | 잘못된 데이터 입력, 데이터의 손상, 데이터 일관성 오류 등으로 인해 데이터의 정확성이 보장되지 않을 수 있음. |
| 제한된 데이터 검색 및 쿼리 기능 | 파일시스템은 기본적인 검색 기능만을 제공하고, 복잡한 데이터 검색 및 쿼리 작업을 수행하기에는 제한적임. |
| 확장성 문제 | 데이터의 양이 증가하거나 DB의 요구사항이 변경될 경우 파일시스템은 데이터 처리에 제한적임. |
| 동시성 및 병행 처리의 문제 | 여러 사용자가 동시에 데이터에 액세스하거나 수정하는 것이 어려움. |
⑵ 데이터베이스관리시스템의 종류 및 특징
① 데이터베이스관리시스템의 기능
ㆍ데이터의 구조화: 파일시스템에서는 각 응용프로그램이 자체적으로 데이터를 관리하기 때문에 중복성이 발생할 수 있으나, DBMS에서는 DB의 테이블이나 컬렉션과 같은 구조를 사용하여 중복된 데이터를 최소화하며, 이를 통해 데이터의 일관성과 무결성을 유지할 수 있음.
ㆍ데이터의 무결성 제약조건: DB의 스키마를 정의하고 제약조건을 설정할 수 있으며, 이를 통해 데이터의 일관성과 무결성을 유지함. 예를 들어 특정 속성은 고유한 값을 가져야 한다거나, 참조 무결성과 같은 제약조건을 설정하여 부모-자식 테이블 간의 정합성을 일치시킬 수 있음.
ㆍ데이터의 동시 접근 제어: 여러 사용자가 동시에 데이터에 접근하고 수정하는 것을 효율 적으로 관리하며, 트랜잭션 개념을 도입하여 여러 작업을 논리적으로 묶고, 트랜잭션(Transaction, DB에서 처리의 기본단위로, 갱신으로 인해 일시적으로 정합하지 않은 데이터가 사용되지 않도록 적절한 구분 기호로 일련의 조작을 묶어서 처리함.) 수준의 잠금 메커니즘을 사용해 충돌을 방지함.
ㆍ데이터의 보안성: 데이터의 보안을 강화하기 위해 사용자 인증과 권한 부여를 통해 접근 제어를 관리하고, 데이터 암호화를 지원하여 데이터의 기밀성을 보호함. 또한 로그 파일을 활용하여 데이터 변경 이력을 기록하고, 복구 기능을 제공함.
ㆍ데이터의 공유와 일관성 유지: 데이터의 공유와 일관성 유지 기능을 제공하여 트랜잭션이 ACID 원칙을 준수하도록 지원함.
▶ 일관성: 트랜잭션이 실행되기 전과 후의 상태가 정의된 규칙과 제약조건을 준수하는 것
▶ ACID: 원자성(Atomicity), 일관성(Consistency), 고립성(Isolation), 지속성(Durability)의 약자로, 트랜잭션의 원자성과 일관성을 보장하며, 동시성과 데이터의 지속성을 유지함.
② 데이터베이스관리시스템의 특징: 데이터 종속성
ㆍDB에서 테이블 내 속성들 사이의 종속 관계를 나타내는 개념으로 '주민등록번호'와 같이 '이름, 나이, 성별' 등의 속성들을 대표할 수 있는 PK와 같은 속성들의 존재 유무와 같은 부분을 확인 및 관리하는 것이 중요함.
ㆍ데이터 종속성을 적절히 관리하지 않은 경우 생길 수 있는 문제들
▶ 데이터 중복과 일관성 문제: 중복 데이터가 테이블에 존재할 수 있고, 이는 용량 낭비와 데이터 일관성 및 정합성을 해칠 수 있음.
▶ 데이터 무결성 문제: 무결성 제약조건이 위배될 수 있고, 정확성과 일관성을 보장할 수 없음.
▶ 유지보수의 어려움: 복잡한 종속성 구조는 DB의 유지보수를 어렵게 만듦. 만약 하나의 속성을 수정하거나 추가할 때, 관련된 모든 종속 속성을 수정해야 한다며, 휴먼에러의 가능성이 증가하고 유지보수 작업의 비용을 증가시킬 수 있음.
▶ 성능 저하: 너무 많은 종속성이 있는 경우 DB의 성능에 영향을 줄 수 있음.
③ 데이터베이스관리시스템의 종류
ㆍ계층형(Hierarchical) DBMS: Tree형태의 계층적, 종속적 관계로 구성한 DBMS
ㆍ네트워크(Network) DBMS: 데이터 구조를 네트워크 상의 노드 형태로 표현하여 각 노드를 대등한 관계로 표현한 DBMS
ㆍ관계형(Relational) DBMS: 데이터를 테이블 형태로 구성하고, 테이블 간의 관계를 기반으로 데이터를 구성한 DBMS
④ 관계형 데이터베이스관리시스템(RDBMS, Relational Database Management System)
ㆍRDBMS: 관계형 데이터베이스를 생성, 조작, 관리하기 위한 소프트웨어 시스템
▶ 데이터를 테이블의 형태로 구성하고, 테이블 간의 관계를 기반으로 데이터를 구성하는 방식으로 Oracle, Mysql, SQL Server, PostgreSQL 등이 있음.
ㆍ주요 특징 및 기능
| 항 목 | 세 부 내 용 |
| 테이블 구조 | 데이터를 테이블로 구성하며, 행과 열의 형태로 데이터를 저장함. 각 테이블은 속성(열)으로 구성되며, 데이터는 이러한 속성들의 값(행)으로 표현됨. |
| 관계 정의 | 테이블 간의 관계를 정의하고 유지하며, 이 관계는 기본키(PK)와 외래키(FK)를 통해 구축됨. |
| 데이터 일관성 | 데이터의 무결성과 일관성을 유지하기 위해 제약조건을 정의하고 적용해야 함. 제약 조건은 데이터의 유효성 검사와 일고나성 유지를 보장함. |
| 질의 언어 | 구조화된 질의 언어인 SQL(Structured Query Language)을 제공하여 데이터 검색, 조작, 조건부 검색 등을 수행함. |
| 데이터의 공유 및 동시성 제어 | 다중 사용자 환경에서 데이터의 공유와 동시성 제어를 지원하며 여러 사용자가 동시에 데이터에 접근하고 조작할 수 있도록 함. |
| 데이터의 보안 | 사용자 권한과 접근 제어를 통해 데이터의 보안을 관리하여 데이터의 무단 접근을 방지하고 데이터의 기밀성을 유지함. |
2. 데이터베이스 이해
1) 데이터베이스 구성요소
① 테이블(Table)
ㆍDB에서 정보를 구조화하여 저장하는 단위로 Entity 또는 Relation이라고도 함.
ㆍ행과 열로 구성된 2차원 구조로 데이터의 집합을 나타내고, 각 테이블은 고유한 이름을 가진 상태로 특정 유형의 데이터를 저장하는 역할을 수행함.
② 속성(Attribute)
ㆍ테이블의 열을 나타내며, 특정 데이터 유형에 대한 정보를 기술하고 Field 또는 Variable이라고 칭함.
ㆍ각 속성은 고유한 이름을 가지며 해당 속성에 저장되는 데이터의 유형을 정의하고, 테이블의 구조를 설명하고 데이터의 특정을 정의하는 데 사용됨.
③ 레코드(Record)
ㆍ테이블의 행을 나타내며, Tuple이라고도 하고, 각 레코드는 테이블의 속성에 해당하는 값들의 집합으로 구성됨.
ㆍDB에서 개별 데이터 항목을 표현하고 행 단위의 작업을 수행하는 데 사용됨.
④ 메타데이터(Metadata)
ㆍ데이터에 대한 데이터로 데이터의 특성, 구조, 의미 등을 설명하는 정보를 의미하고 DB 시스템에서 데이터를 관리하고 사용하는 데 필요한 정보를 제공함
ㆍ테이블 속성 이름, 데이터 유형, 제약조건, 관계 등의 정보를 포함하며, 이를 통해 데이터의 의미를 이해하고 해석할 수 있으며, 테이블 이름, 속성, 인덱스 정보 등을 포함하여 DB에서 원하는 데이터를 식별하고 검색하는 데 도움을 줌.
ㆍ테이블 간의 관계, 제약조건, 외래키 등을 정의하여 데이터의 일관성 무결성을 보장하며, 데이터의 유형, 형식, 크기 통계 정보 등을 포함하여 데이터 분석 및 가공작업에 필요한 정보를 제공함.
ㆍ접근권한, 사용자권한, 보안 제약조건의 정보를 포함하여 데이터의 보안과 접근 제어를 관리함.
⑤ 데이터 딕셔너리(Data Dictionary)
ㆍDB시스템에서 사용되는 데이터 구조와 메타데이터에 대한 정보를 저장하고 관리하는 역할을 하며, DB 객체(테이블, 속성, 제약조건 등)의 정의, 구조, 속성, 통계 등의 데이터에 대한 설명과 정보를 포함함.
ㆍDBMS에서 중요한 역할을 하며 데이터의 정확성과 일관성을 유지하는 데 도움을 줌.
⑥ 트랜잭션 관리자(Transaction Manager)
ㆍDB에서 트랜잭션의 관리와 제어를 담당하는 역할을 하며, 트랜잭션의 시작, 종료, 병합, 롤백 등의 작업을 처리하여 데이터의 일관성과 동시성 제어를 관리함.
ㆍ트랜잭션은 DB에서 원자와 같은 작업 단위로 간주되며, 여러 개의 데이터 조작 작업을 하나의 논리적인 단위로 묶어 일관성과 안전성을 보장함.
⑦ 저장 데이터 관리자
ㆍDB의 저장구조와 데이터의 물리적인 저장, 접근, 관리를 담당하는 역할을 하며, DB의 블록 할당, 파일시스템, 인덱스 구조, 버퍼 관리 등을 관리하여 데이터의 효율적인 저장과 검색을 지원함.
ㆍ데이터의 저장 방법과 구조에 대한 결정, 디스크 공간 관리, 인덱스 생성과 유지, DB 파일 관리 등의 작업을 수행함.
⑧ 질의 처리기(Query Processor)
ㆍ사용자가 질의(SQL)를 처리하고 DB로부터 원하는 정보를 추출하는 역할을 하며, 사용자가 요청한 질의를 해석하고, 최적의 실행 계획을 생성하여 DB로부터 데이터를 검색하거나 조작함.
2) 데이터베이스 구조
① 스키마(Schema)
ㆍ데이터 구조와 제약조건을 명세하는 것으로, 개체, 속성, 관계의 정의와 그들이 유지해야 할 제약조건을 포함하며, DB고나리 관점에서 스키마는 외부, 개념, 내부로 구분됨.(Three Schema 구조)
▶ 외부 스키마: 사용자나 응용 프로그램의 관점에서 DB를 정의하며, 특정 사용자 그룹이나 응용 프로그램에 필요한 데이터의 논리적 구조와 접근 방법을 정의함.
- 각각의 외부 스키마는 해당 사용자나 응용 프로그램이 필요로 하는 데이터의 부분집합에 대한 뷰(View)로서 동작함.
- DB 시스템에서 개별적으로 정의되며, 다수의 외부 스키마가 존재할 수 있음.
▶ 개념 스키마: 전체 DB의 논리적 구조 정의로 모든 외부 스키마의 통합된 뷰로서 DB의 전체적인 구조와 데이터 간의 관계를 나타냄.
- DB 시스템의 관리 및 조작을 위한 기반을 제공하며, 데이터의 일관성과 무결성을 유지하는 역할을 함.
▶ 내부 스키마: 데이터의 물리적 구조 정의
- 데이터가 디스크에 저장되는 방식, 인덱스 구조, 저장 위치 등과 같은 물리적 세부 사항을 정의하며 DB 시스템의 성능 향상을 위해 최적화된 구조로 데이터를 관리함.
② 데이터베이스 언어
ㆍ데이터베이스는 데이터를 관리하는 시스템이며, DB에는 데이터가 물리적인 파일 형태로 저장되어 있지만 직접 파일을 열어 데이터를 확인하는 것이 아닌 질의 언어를 사용하여 저장된 데이터를 조회, 입력, 수정, 삭제하는 등의 조작을 수행하고, 테이블을 비롯한 다양한 개체를 생성하고 제어함.
ㆍ데이터 언어: DB를 정의하고 접근하기 위한 시스템과의 통신을 위해 사용되는 언어
| 항 목 | 세 부 내 용 |
| 데이터 정의어 (DDL, Data Definition Language) |
DB의 구조와 스키마를 정의하는 데 사용하며, DB 객체의 생성, 수정, 삭제를 담당함.(CREATE, ALTER, DROP) |
| 데이터 조작어 (DML, Data Manipulation Language) |
DB에서 데이터를 조작하는 데 사용하며, 데이터의 검색, 삽입, 수정, 삭제 등의 작업을 수행함.(SELECT, INSERT, UPDATE, DELETE) |
| 데이터 제어어 (DCL, Data Control Language) |
DB에 접근하는 사용자나 응용 프로그램에 대한 권한을 부여하거나 제거하는 작업을 수행함.(GRANT, REVOKE) |
3) 키(Key), 변수의 개념
① 키(Key)
ㆍDB에서 레코드를 고유하게 식별하는 역할을 하는 속성(열) 또는 속성들의 조합으로 데이터의 고유성과 무결성을 보장하며, 데이터의 식별 및 검색에 사용됨.
ㆍ종류
| 항 목 | 세 부 내 용 |
| 슈퍼키(Super Key) | 테이블 내에서 레코드를 고유하게 식별할 수 있는 속성 또는 속성들의 조합으로 테이블 내의 모든 레코드를 고유하게 식별할 수 있지만, 최소성 조건을 만족시키지 않을 수 있음. |
| 후보키(Candidate Key) | 테이블에서 각 레코드를 고유하게 식별할 수 있는 속성 또는 속성들의 조합으로 슈퍼키의 특징을 가지면서도 최소성 조건을 만족함. 후보키는 기본 키로 사용될 수 있으며, 후보키 중에서 기본키를 선정함. |
| 기본키(Primary Key) | 테이블에서 각 레코드를 고유하게 식별하기 위해 선택된 키로 후보키 중에서 선정되며, 테이블 내에 중복된 값이ㅇㅂ 없어야하고 NULL값을 가질 수 없음. |
| 대체키(Alternate Key) | 기본키가 될 수 있는 후보키 중 기본키로 사용되지 않는 키 |
| 외래키(Foreign Key) | 한 테이블에서 다른 테이블의 기본키를 참조하는 키로 테이블 간의 관계를 맺을 수 있고, 참조 무결성을 유지할 수 있음. 테이블 간의 관계를 정의하고 데이터의 일관성을 유지하는 데 사용됨. |
② 변수(Variable)
ㆍ값을 저장하고 참조할 수 있는 공간으로 데이터 처리 및 분석에 사용되며, 값을 저장하고 조작함으로써 원하는 결과를 얻을 수 있게 함
ㆍ프로그래밍에서 변수는 데이터를 저장하고 처리하는 데 사용되며, 통계에서 변수는 데이터의 특성을 기록하고 분석하는 데 사용됨.
ㆍ데이터를 나타내기 위해 변수의 이름을 부여하고 해당 이름을 통해 변수에 접근할 수 있음.
ㆍ변수는 특정한 데이터 유형을 가지며, 해당 유형에 따라 저장가능한 값의 종류와 연산이 제한될 수 있고, 독립변수와 종속변수와 같은 종류가 있음.
ㆍ종류
| 항 목 | 세 부 내 용 |
| 이산변수 (Discrete Variable) |
정수 또는 유한한 값 중 하나를 가지는 변수로 연속적인 값을 가지지 않음. 개수나 빈도와 같은 계수적인 측면에서 분석될 수 있음. 예시: 주사위 눈의 개수, 가족 구성원 수 등 |
| 연속변수 (Continuous Variable) |
실수 형태로 연속적인 값을 가지는 변수로 무한한 값을 가질 수 있음. 측정이나 관찰에 따라 다양한 값을 가지며, 측정된 값의 정밀도와 소수점 자릿수에 따라 다를 수 있음. 예시: 사람의 키, 몸무게, 온도 등 |
| 명목형 변수 (Nominal Variable) |
범주를 표현하는 변수로 명목적인 라벨이나 카테고리를 가짐. 값들이 상호 배타적인 범주로 분류되며, 순서나 계층구조가 없음. 범주간의 차이를 표현하거나 범주 간의 관계를 정량적으로 파악하는 데 사용될 수 있음. 예시: 동물의 종류, 혈액형 등 |
| 순서형 변수 (Ordinal Variable) |
범주를 순서대로 나타내는 변수로 상대적인 크기나 순서를 가지며, 범주 간의 순서 또는 계층구조가 있음. 예시: 학업 성적의 등급 등 |
| 파생변수 (Derived Variable) |
기존 변수를 이용하여 계산, 변형, 또는 조합하여 생성된 변수로 주어진 데이터나 변수로부터 파생되며, 원래 변수들로부터 얻은 정보나 의미를 나타내는 새로운 변수임. 예시: 키와 몸무게로부터 계산한 BMI 계수 등 |
| 요약변수 (Summary Variable) |
데이터의 특성을 요약하여 표현한 변수로 여러개의 관측치를 대표하는 값으로 축약된 형태를 가짐. 데이터의 집계나 통계 계산에 사용됨. 예시: 평균, 중앙값, 최댓값, 최솟값 등의 통계량 |
| 시계열 변수 (Time Series Variable) |
시간에 따라 변화하는 값을 갖는 변수로 일정한 간격으로 측정되거나 관찰되는 시간 데이터를 기반으로 함. 시간 경과에 따른 패턴, 추세, 계절성 등을 파악하거나 예측하는 데 사용함. 예시: 매일의 주가, 매월의 판매량, 연간 기후 데이터 등 |
4) 분산 데이터베이스
① 분산 데이터베이스
ㆍ물리적으로 분산된 DB 시스템을 네트워크로 연결해 사용자가 논리적으로는 하나의 중앙 집중식 DB 시스템처럼 사용할 수 있도록 한 것
② 분산 데이터베이스시스템의 주요 구성 요소
ㆍ분산 처리기(Distributed Processor): 지역별로 필요한 데이터를 처리할 수 있는 지역 컴퓨터(local computer)로, 각 지역의 데이터베이스를 자체적으로 관리하는 DBMS를 별도로 가지고 있음.
ㆍ분산 데이터베이스(Distributed Database): 물리적으로 분산된 지역 DB로 해당 지역에서 가장 많이 사용하는 데이터를 저장함.
ㆍ통신 네트워크: 분산 처리기는 통신 네트워크를 통해 자원을 공유하며, 특정 통신 규약에 따라 데이터를 전송함.
③ 분산 데이터베이스 시스템의 장단점
ㆍ장점
▶ 신뢰성과 가용성 증대: 장애 발생 시 다른 지역의 DB를 이용해 작업을 계속 수행할 수 있음.
▶ 지역 자치성과 효율성 증대: DB를 지역별로 독립적으로 관리하므로 데이터 요청에 대한 응답 시간을 줄이고 통신 비용도 절약됨.
▶ 확장성 증대: 처리할 데이터 양이 증가하면 새로운 지역에 DB를 설치하여 운영하면 됨.
ㆍ단점
▶ 중앙 집중식 시스템에 비해 설계 및 구축 비용이 많이 발생하고, 추가 통신 비용이나 처리 비용이 발생함.
▶ 여러 지역에 대한 관리가 복잡하고, 오류의 잠재성과 데이터 무결성에 대한 위협이 증대하며, 불규칙한 응답속도를 가지고 있음.
④ 분산 데이터베이스 시스템의 투명성 유형
ㆍ분할 투명성: 하나의 논리적 관계가 여러 단편으로 분할되어 각 단편의 사본이 여러 장소에 저장됨.
ㆍ위치 투명성: 사용하는 데이터의 저장 장소를 명시할 필요가 없으며, 위치 정보는 시스템 카탈로그에 유지됨.
ㆍ지역사상 투명성: 지역 DBMS와 물리적 DB사이에 연계(Mapping)를 보장함.
ㆍ중복 투명성: DB 객체가 여러 사이트에 중복되어 있는지 알 필요가 없음.
ㆍ장애 투명성: 구성요소의 장애와 무관한 트랜잭션(Transaction)의 원자성 유지
ㆍ병행 투명성: 다수의 트랜잭션을 동시에 수행해도 트랜잭션의 결과는 영향을 받지 않음.
Section 03 데이터 활용
1. 데이터 가공
① 데이터 오류: 데이터 집합 내에 부정확하거나 잘못된 정보가 포함된 것
ㆍ입력 실수, 기술적 결함, 하드웨어 오작동, 데이터 수집, 저장, 전송 과정에서 다양한 원인으로 인해 발생함.
ㆍ데이터 관리 및 분석에 심각한 오류를 초래하므로 데이터의 정확성과 신뢰성을 보장하기 위해 유효성 검사와 검증 프로세스가 필수적임.
| 종 류 | 세 부 내 용 |
| 오타 오류 | 데이터를 수동으로 입력할 때 실수로 발생하는 오류 |
| 중복 항목 | 동일 데이터를 데이터 집합에 2번 이상 입력할 때 발생 |
| 누락 데이터 | 불완전한 데이터 수집 또는 입력 중 특정 데이터 포인트가 누락되는 경우에 발생함 |
| 잘못된 서식 | 데이터가 필요한 표준에 따라 올바르게 포맷되지 않았을 때 발생 |
| 이상값 | 데이터 범위를 크게 벗어나는 데이터 포인트로 측정 오류, 데이터 손상 또는 기타 이상 징후로 인해 발생 |
| 잘못 정렬된 데이터 | DB나 스프레드시트에서 데이터가 없어 잘못 정렬되어 값이 잘못된 범주나 레이블에 연결될 수 있음. |
| 계산 오류 | 데이터에 대한 수학적 또는 통계적 계산이 잘못 수행될 때 발생 |
② 데이터 정제: 데이터의 품질과 정확성을 높이는 작업
ㆍ결측값 처리
▶ 결측값 식별: 데이터 세트에 결측값이 있는지 확인하고, 결측값이 발생하는 패턴과 원인을 파악
▶ 결측값 처리: 결측값이 있는 행 또는 열을 삭제하거나 적절한 추정치(평균, 중앙값, 회귀 대입 등)로 결측값을 채우거나 다중 대입과 같은 기법을 사용(단, 결측값 대입의 잠재적 영향과 편향을 고려해야 함)
ㆍ중복값 제거
▶ 중복값 식별: 특정 변수 또는 변수의 조합을 기준으로 각 행을 비교하여 데이터 세트에 중복된 항목이 있는지 확인
▶ 중복값 제거: 첫 번째 항목 유지, 마지막 항목 유지, 모든 중복 항목 제거 등의 방법을 사용하여 중복값 제거
ㆍ불일치 데이터 처리
▶ 불일치 데이터 식별: 일관되지 않은 데이터의 형식, 값, 표현 등을 식별
▶ 형식 표준화: 데이터 형식을 일관된 표현으로 변환하여 표준화
▶ 오류 수정: 데이터 세트에서 발견된 데이터 입력 오류나 불일치를 확인하고 수정
ㆍ이상값 처리
▶ 이상값 식별: 데이터 범위를 크게 벗어난 극단적인 값 감지
▶ 상황적 이해: 도메인 지식과 데이터 분석 작업을 고려하여 이상값 판단
▶ 처리 방법: 통계적 방법을 사용하여 이상 값을 제거 또는 반환
ㆍ데이터 유효성 검사
▶ 사전에 정의된 규칙 또는 제약조건에 따라 데이터의 유효성 검사
▶ 외부 데이터 또는 알려진 참조와 상호 교차하여 데이터의 신뢰성과 정확성 검증
③ 데이터 변환: 데이터의 원래 형식을 분석 또는 모델링에 적합한 형식으로 변환하는 작업
| 항 목 | 세 부 내 용 |
| 정규화 / 표준화 | 정규화: 서로 다른 배율의 영향을 없애고 모든 변수를 비슷한 수준으로 맞추기 위해 숫자 데이터의 배율을 0과 1사이의 범위로 재조장하는 방법 표준화: 변수의 단위나 분포가 다른 경우 변수의 척도를 맞추기 위해 숫자 데이터를 평균 0, 표준편차 1이 되도록 변환하는 작업 |
| 로그 변환 | 데이터 분포가 왜곡된 경우 데이터의 분포를 대칭적으로 만들어 극단적인 값의 영향을 줄이기 위해 데이터에 로그 함수를 적용하는 작업 |
| 구간화(Binning) | 연속형 변수를 범주형 또는 순서형 변수로 변환하거나 숫자 값의 변화로 인한 영향을 줄이기 위해 연속형 데이터를 불연속 구간 차원 또는 간격으로 범주화 |
| 범주형 변수 인코딩 | 원한(One-Hot) 인코딩: 범주형 변수를 0과 1의 이진 벡터로 변환 레이블(Label) 인코딩: 범주형 변수의 각 범주에 숫자 값을 할당 |
| 날짜 및 시간 처리 | 분할: 날짜/시간 데이터를 년, 월, 일, 시, 분 등으로 분할 파생: 날짜/시간 데이터로부터 시간대(오전, 오후, 저녁), 요일 또는 계절 등의 파생변수를 생성 |
| 데이터 집계 및 형태변환 | 데이터 집계: 특정 변수의 합계, 평균, 최댓값, 최솟값 등을 계산하여 특정 기준에 따라 여러 행 또는 레코드를 단일 요약 행으로 집계 |
| 차원 축소 | 주성분 분석(PCA, Principal Component Analysis): 데이터의 분포를 최대한 보전하면서 고차원 데이터를 저차원 데이터로 변환하는 대표적인 차원 축소기법 특징 선택(Feature Selection): 모델 구성을 위한 특징(변수) 선택 |
④ 데이터 분리: 데이터 처리 분석, 모델링 또는 유효성 검사를 목적으로 특정 기준에 따라 데이터를 분할하는 작업
ㆍ데이터 세트 분할
▶ 훈련 세트(Training Set): 모델의 학습을 위한 데이터 세트
▶ 검증 세트(Validation Set): 모델을 조정하고 평가하기 위한 데이터 세트
▶ 테스트 세트(Test Set): 모델의 성능을 평가하기 위한 세트
ㆍ교차 검증
▶ 모델 성능의 추정과 일반화 성능을 평가하기 위해서 데이터 세트를 여러 하위 집합(fold)으로 분리한 후 일부 폴드는 테스트 세트로 사용하고 나머지 폴드는 훈련 세트로 사용
ㆍ표본 추출
▶ 계층적 표본 추출: 분포가 불균형하거나 계층화된 데이터 세트에서 클래스 또는 그룹의 상대적인 비율을 유지하는 방식으로 데이터 추출
▶ 무작위 표본 추출: 데이터 세트에서 무작위로 데이터 추출
ㆍ시간 기반 분할
▶ 시계열 또는 순차적 데이터를 처리하기 위해 특정 시점 또는 기간을 기준으로 데이터 세트를 분할
⑤ 데이터 결합: 다수의 데이터 세트를 하나의 통합된 데이터 세트로 병합하거나 통합하는 작업
ㆍUNION: 스키마 구조가 동일한 테이블 2개를 병합하는 방법(행수만 증가)
ㆍJOIN: 공통 키 또는 식별자를 기반으로 데이터세트들을 결합하는 방법으로, Inner, Left, Right, Full Outer, Cross JOIN 등이 있음.
ㆍ추가: 기존 데이터 세트에 새로운 관측값(행) 또는 변수(열) 추가
ㆍ데이터 혼합: 서로 다른 구조 또는 변수를 가진 서로 다른 소스의 데이터 세트 사이에 일치하는 정보를 식별하고 정렬하여 데이터 세트를 통합함.
2. 데이터 관리
① 데이터 수집 및 변환: 다양한 소스에서 데이터를 수집 및 구성하고 이를 분석 또는 저장에 적합한 구조화된 형식으로 변환하는 프로세스
| 프 로 세 스 | 세 부 내 용 |
| 데이터 요구사항 정의 | 수집해야 하는 구체적인 데이터와 수집 목적을 결정함 목표를 달성하는 데 필요한 속성, 형식 및 구조를 명확하게 정의함 |
| 데이터 소스 식별 | DB, 스프레드시트, API, 웹 스크래핑, 로그 파일, IoT 장치, 소셜 미디어 플랫폼 등과 같은 소스들을 식별하는 단계임. |
| 데이터 수집 | 데이터 추출: SQL 쿼리, API 요청, 파일 다운로드 또는 웹 스크래핑 기술 등을 사용하여 식별된 소스에서 데이터 추출 데이터 통합: 여러 소스의 데이터를 단일의 데이터 세트로 통합하고, 호환성, 일관성 및 데이터 품질관리를 진행 |
| 데이터 변환 | 데이터 정리: 데이터 세트의 불일치, 오류 또는 중복을 제거 및 수정 데이터 서식: 데이터를 분석 또는 저장에 적합한 일관된 형식으로 변환 데이터 집계: 특정 속성별로 데이터를 집계하여 요약 데이터를 생성 데이터 보강: 외부 소스에서 관련 데이터를 추가하여 데이터 세트 보강 |
| 데이터 검증 및 품질보증 | 데이터 무결성 검증: 데이터의 정확성, 일관성 및 완전성 검사 실시 품질 보증: 데이터 품질 검사 및 유효성 검사 규칙을 구현하여 이상 징후, 이상값 또는 데이터 품질 문제를 식별하고 해결 |
| 데이터 스토리지 | 변환된 데이터의 볼륨, 구조 및 접근 요구 사항에 따라 적절한 데이터 스토리지 솔루션을 결정 대표적인 데이터 스토리지 솔루션으로는 RDBMS, NoSQL DB, DW 또는 Microsoft, Amazon, Google등이 제공하는 클라우드 기반 솔루션 등이 있음. |
② 데이터 적재 및 저장
ㆍ데이터의 효과적인 적재와 저장은 데이터의 무결성, 접근성 및 효율성 유지에 도움을 줌.
ㆍ데이터 적재
▶ 추출, 변환, 로드(ETL, Extract, Transform, Load): 다양한 소스에서 데이터를 추출하고 통합된 형식을 변환한 후 대상 시스템에 로드하는 프로세스
▶ 일괄처리: 데이터를 관리 가능한 단위(Chunk)로 나누고 일괄적으로 적재
▶ 실시간 처리: 스트리밍 데이터의 발생과 동시에 실시간으로 데이터를 처리하고 적재
ㆍ데이터 저장
| 항 목 | 세 부 내 용 |
| 관계형 데이터베이스 | 구조화된 데이터를 테이블 형식을 저장하는 DB로 MySQL, Oracle, SQL Server 등이 있음. |
| NoSQL 데이터베이스 | 비정형 또는 반정형 데이터를 저장하는 DB로 MongoDB, Cassandra, Redis 등이 있음. |
| 데이터 웨어하우스 | 다양한 소스에서 수집된 대량의 데이터를 저장, 관리 및 분석하도록 설계된 중앙 저장소로, 비즈니스 인텔리전스를 위한 플랫폼이며, Amazon Redshift, Google Bigquery, Snowflake등이 있음. |
| 분산 파일시스템 | 대량의 비정형 데이터를 저장하기 위한 시스템으로 HDFS(Hadoop Distributed File System), Google File System등이 있음. |
ㆍ데이터 백업 및 복구
▶ 정기적 백업: 데이터 손실 또는 시스템 장애 발생 시 데이터 가용성과 복구를 보장하기 위해 정기적이고 자동화된 데이터 백업 수행
▶ 복원 테스트: 데이터 복원 프로세스를 주기적으로 테스트하여 백업의 무결성을 검증하고 데이터를 성공적으로 복구할 수 있는지 확인
ㆍ데이터 보안
▶ 접근 제어: 데이터의 접근 권한을 제어하고 인증하는 메커니즘 구현
▶ 암호화: 암호화 기술을 사용하여 미사용 데이터와 전송 중인 데이터를 보호함.
▶ 개인정보 보호 규정 준수: 개인정보 및 민감한 데이터 보호 규정 준수
ㆍ모니터링 및 유지관리
▶ 데이터 저장 및 저장 프로세스 추적, 이상 징후 감지, 데이터 스토리지 인프라의 상태와 성능을 주기적으로 모니터링하고 관리하여 데이터 스토리지의 환경을 효율적으로 안정적으로 유지
③ 데이터 보안 및 개인정보보호
ㆍ데이터 보안: 무단 접근, 공개, 변경, 파기로부터 데이터를 보호하기 위한 기술적, 관리적, 물리적 제어 포함
ㆍ데이터 분류: 민감도와 중요도에 따라 공개, 내부, 기밀, 제한 등으로 데이터를 분류하고 적절한 수준의 보안 제어 결정
ㆍ접근제어
▶ 사용자 인증: 데이터 사용자를 확인하기 위해 PW, MFA(Multi Factor Authentication), 생체 인증 등과 같은 인증 메커니즘 구현
▶ 사용자 권한 부여: 사용자 역할과 권한에 따라 세분된 접근 제어 설
ㆍ데이터 백업 및 복구
▶ 정기적 백업: 정기적이고 자동화된 데이터 백업 작업 수행
▶ 오프사이트 스토리지(Off-site Storage): 물리적 재해 또는 시스템 장애 발생 시 데이터 가용성을 보장하기 위해 백업을 안전한 외부에 저장
▶ 재해 복구 계획: 장애 발생 시 데이터 복원, 시스템 복구, 비즈니스 연속성을 위한 절차를 명시하는 포괄적인 재해 복구 계획 수립
ㆍ네트워크 보안
▶ 방화벽: 수신 및 발신 네트워크의 트래픽을 모니터링하고 제어하는 솔루션
▶ 침입 탐지 및 방지 시스템(IDS/IPS, Intrusion Detection System/Intrusion Prevention System): 침입 시도, Malware, 무단 접근 등의 네트워크 공격을 탐지하고 방지하는 시스템
▶ Wi-Fi 네트워크 보안: 비밀번호 변경 및 펌웨어 업데이트를 정기적으로 실시
ㆍ개인정보보호 규정 준수
▶ 규정 준수: 관련된 데이터 개인정보보호 규정 이해 및 준수
▶ 개인정보 비식별화: 가명화 또는 익명화를 이용하여 개인정보 비식별화
ㆍ정기적인 보안 업데이트 및 패치 관리
▶ 소프트웨어 공급업체가 제공하는 업데이트와 보안 패치를 정기적으로 설치
ㆍ물리적 보안 조치
▶ 데이터 센터 보안: 접근 제한, 비디오 감시, 환경 제어 등 데이터 센터와 서버실 보호를 위한 물리적인 보안 조치 실시
▶ 보안 스토리지: 무단 접근 및 도난 방지를 위해 저장매체를 안전하게 보관
3. 비즈니스 인텔리전스
① 비즈니스 인텔리전스(BI, Business Intelligence)의 개념
ㆍ조직에서 데이터를 분석하여 실행 가능한 통찰과 의미 있는 정보를 생성하기 위해 사용하는 기술, 전략, 프로세스
ㆍ비즈니스 운영, 추세 및 패턴에 대한 포괄적인 뷰를 제공하여 사업기회를 파악하고 문제를 해결하며 전략적 의사결정을 지원하는 것을 목적으로 함.
② 비즈니스 인텔리전스 관련 개념
ㆍ데이터 통합: DB, 스프레드시트, 엔터프라이즈 시스템, 외부 API 등과 같은 여러 소스 데이터의 통합을 기반으로 하며, 통합된 데이터는 데이터 정제 및 변화 과정을 거친 후 분석에 사용함.
ㆍ데이터 웨어하우징: 다양한 소스의 데이터를 중앙 집중식 레포지토리인 데이터 웨어하우스에 통합하여 분석에 최적화된 데이터를 제공함.
ㆍ데이터 모델링: 데이터의 논리적 표현을 생성하는 것으로 테이블 사이의 관계, 계층구조, 차원, 측정값을 정의
ㆍ데이터 분석: 설명적 분석, 진단적 분석, 예측적 분석, 처방적 분석을 활용하여 데이터에서 비즈니스에 유용한 통찰 발견
ㆍ데이터 시각화: 대시보드, 차트, 그래프 등을 이용하여 데이터를 시각적으로 표현
ㆍ데이터 마이닝: 통계분석, 머신러닝, 인공지능 등을 활용하여 대규모 데이터 세트 내에서 숨겨진 패턴, 관계 및 추세를 발견하는 기술과 방법
ㆍ셀프서비스 비즈니스 인텔리전스(Self-service Business Intelligence): 비즈니스 사용자가 IT팀 또는 기술팀에 의존하지 않고 독립적으로 데이터에 접근하여 데이터를 탐색하고 분석하는 것
ㆍ데이터 거버넌스: 다양한 정책과 표준을 통해 데이터의 보안, 개인정보보호, 정확성, 가용성, 사용성을 보장하기 위해 수행하는 모든 작업을 의미하며, 데이터 거버넌스의 목표는 안전한 방식으로 손쉽게 접근 가능한 고품질 데이터를 유지하고 관리하는 것임.
ㆍ지속적인 개선: BI는 지속적인 모니터링, 분석 및 개선이 수반되는 반복적인 프로세스로 조직은 비즈니스 상황을 추적하고, 전략의 효과를 측정하고, 성과를 개선하기 위해 필요한 조정을 지속적으로 수행함.
③ BI와 데이터 기반 의사결정
ㆍBI는 데이터 기반 의사결정에 필요한 프레임워크, 도구 및 통찰을 제공하며 이를 통해 조직은 데이터를 효과적으로 활용하고, 의미 있는 통찰을 얻어 정보에 입각한 의사결정을 내림으로써 비즈니스 성공과 경쟁력을 높일 수 있음.
ㆍ데이터 기반 의사결정
▶ 관련 데이터의 분석과 해석을 기반으로 정보에 입각한 선택과 전략적 계획을 세우는 접근 방식
▶ 데이터를 수집, 정리, 분석, 해석하여 통찰을 얻고 의사결정 프로세스를 추진하는 것을 포함함.
▶ 정확하고 신뢰할 수 있는 데이터를 사용하여 의사결정을 수행함으로써 편견을 줄이고 객관성 제고
ㆍBI는 데이터 기반 의사결정의 토대가 되며, BI가 제공한 통찰을 통해 의사결정자는 비즈니스의 현재 상태를 이해하고, 기회를 파악하고 문제를 진단할 수 있음.
ㆍBI는 의사결정자에게 시의적절하고 정확한 정보를 제공하며, 이를 위해 데이터 수집 및 통합이 보장되어야 함.
ㆍBI는 의사결정 프로세스에 증거 기반 접근 방식을 제공하여 조직의 목표와 목적에 부합하는 의사결정을 내릴 가능성을 제고함.
④ 비즈니스 인텔리전스의 활용
ㆍBI를 효과적으로 사용하려면 기술, 데이터 거버넌스, 데이터 기반 사고방식이 필수적이며 이를 위한 단계와 고려사항이 필요함.
ㆍ비즈니스 목표정의: 비즈니스 목표와 BI를 사용하여 해결하고자 하는 구체적인 질문 또는 과제를 명확하게 정의
ㆍ핵심성과지표 식별: 비즈니스 목표와 일치하고 비즈니스 운영 및 성과에 대한 의미 있는 통찰을 제공하는 KPI(Key Performance Indicator, 조직의 성과를 모니터링하고 목표에 대한 진행상황을 추적하는 데 도움이 되는 측정 가능한 지표)를 설정함.
ㆍ데이터 수집 및 통합: DB, 스프레드시트, 엔터프라이즈 시스템, API 등과 같은 다양한 소스에서 데이터를 수집하고 통합하고 정리하여 정확하고 일관성 있는 데이터를 준비
▶ 중복값 제거, 이상값 처리, 결측값 처리 등의 데이터 정제와 정규화, 표준화, 인코딩 등의 데이터 변환 작업 포함
ㆍ BI 도구 선택
▶사용자의 요구사항을 충족하는 BI 도구 또는 플랫폼을 선택해야 하며, 선택 시에는 편의성, 확장성, 데이터 시각화 기능, 보고 옵션, 기존 시스템과의 통합과 같은 요소들을 고려해야 함.
ㆍ대시보드 디자인 및 개발: 비즈니스에 의미가 있고 사용자가 이해하기 쉬운 형식으로 데이터를 표현하고 직관적, 시각적으로 매력적인 대시보드를 디자인하고 개발
▶ 주요 지표, 차트 및 시각화를 적절히 배치하여 비즈니스 성과에 대한 포괄적인 개요를 제공하고 대시보드 디자인 시 대상 고객의 구체적인 요구사항에 대한 면밀한 수집 및 분석이 중요함.
ㆍ데이터 분석 수행: BI 도구를 사용하여 데이터의 추세, 패턴, 상관관계, 이상 징후 등을 탐색
▶ 통계 기법, 데이터 마이닝, 데이터 시각화 등의 데이터 분석 방법을 사용하여 비즈니스에 대한 깊은 이해와 통찰을 발견하는 것을 목표로 함.
ㆍ보고서 및 시각화 생성: 분석을 기반으로 보고서와 시각화를 생성하여 분석 결과를 의사결정자에 효과적으로 전달
▶ 명확하고 간결하며 시각적으로 매력적인 방식으로 정보를 제시해야 하고, 차트, 그래프, 표 내러티브를 사용하여 주요 결과를 강조하고 스토리텔링 기법을 사용하는 것이 필요함.
ㆍ성과 모니터링 및 추적: BI 솔루션을 사용하여 비즈니스 성과를 지속적으로 모니터링하고 추적
▶ 경고 및 알림을 설정하여 지표의 편차 또는 이상 징후를 사전에 식별하고 확인할 수 있도록 해야 하며, 대시보드와 보고서를 정기적으로 검토하여 변경 사항에 대한 정보를 파악하고 필요시 적시에 조치를 시행
ㆍ협업 및 통찰 공유: 팀과 부서 간의 협업을 장려하고 통찰을 공유하여 데이터 기반 의사결정 문화를 조성하고 정착하도록 노력
ㆍ반복 및 개선: 반복적인 프로세스로 구현 효과를 지속적으로 평가하고 피드백을 수집하여 데이터, KPI, 데이터 시각화 등을 지속적으로 개선하는 것이 중요함
ㆍ사용자 훈련 및 교육: BI를 효과적으로 활용할 수 있도록 조직 내 사용자에게 교육 및 훈련 프로그램 제공
▶ 사용자가 독립적으로 데이터를 탐색하고 정보에 기반한 의사결정을 내릴 수 있도록 장려하여 데이터 기반 문화 조성
'IT & 데이터 사이언스 > 데이터 분석 & 시각화' 카테고리의 다른 글
| [경영정보시각화능력] Chapter 03 경영정보시각화 디자인 (0) | 2024.05.16 |
|---|---|
| [경영정보시각화능력] Chapter 01 경영정보 일반(4) (0) | 2024.05.10 |
| [경영정보시각화능력] Chapter 01 경영정보 일반(3) (0) | 2024.05.09 |
| [경영정보시각화능력] Chapter 01 경영정보 일반(2) (0) | 2024.05.09 |
| [경영정보시각화능력] Chapter 01 경영정보 일반(1) (0) | 2024.05.07 |




댓글