안녕하세요. 바른 호랑이입니다.
이번 게시글에서는 데이터 형식에 관해서 알아볼 예정입니다.
인터넷, SNS와 같은 정보통신기술의 급속한 발달 덕분에 우리의 생활은 다방면에서 빠르게 변화해왔고, 그 속도는 점점 더 빨라지고 있습니다. 빅데이터라는 키워드가 21세기의 핵심 키워드가 될 정도로 데이터의 중요성은 그 어느때보다 커지고 있고, 이를 적절히 분석하여 원하는 정보를 추출하여 의사결정에 사용하는 절차가 점점 더 중요해지고 있다고 할 수 있습니다. 빅데이터를 간단히 설명하면 데이터 중에서 사용 및 분석이 가능한 모든 것의 총칭이라고 할 수 있으며, 이를 어떻게 활용하느냐에 따라 같은 원인을 가지고도 다양한 결과를 도출할 수 있습니다.
빅데이터란 사실 완전히 새로운 개념이라기 보다는 마이크로칩, 센서, 인터넷, 클라우드 컴퓨팅 기술 등과 같은 기술 발전에 따라 데이터의 종류와 생산량이 기하급수적으로 증대되고, 그에 맞춰 데이터 수집 및 분석기술이 발전하면서 그 중요성이 증폭되며 대두된 개념이라고 할 수 있습니다. 고대시대의 주판에서부터 시작한 데이터의 역사는 20세기 전자공학의 발전과 21세기 스마트폰의 등장으로 중대한 변곡점을 맞이하게 되었습니다. 하루에도 셀 수도 없을 만큼 쏟아지는 데이터들은 다양한 형식을 가지고 있고, 형식에 따라 수집, 추출, 변환, 분석 방법이 모두 다릅니다. 데이터 형식에 맞춰 효과적인 분석을 해야지만 원하는 정보를 만들어서 최적의 의사결정을 할 수 있기에 데이터 분석을 제대로 하기위해서는 데이터 형식에 대한 이해가 선행되어야 한다고 할 수 있습니다.
데이터의 형식은 구조화 유무와 정도에 따라 크게 3가지로 분류할 수 있습니다.
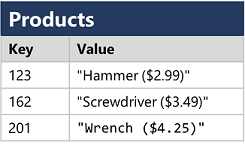
1. 정형데이터 : 고정된 스키마를 준수하여 모든 데이터가 동일한 필드 또는 속성을 갖는 데이터

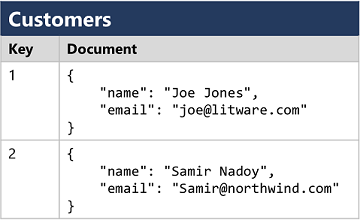
2. 반정형 데이터 : 얼마간의 구조는 있으나 각 엔터티, 인스턴스간의 약간의 차이가 허용되는 정보(JSON이 대표적)
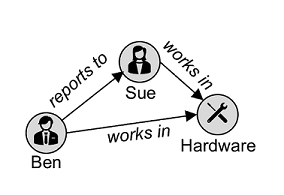
3. 비정형 데이터 : 문서, 이미지, 오디오 및 비디오 데이터와 같이 특정한 구조를 갖지 않는 데이터
일반적으로 조직들은 데이터를 위의 3가지 형식으로 세부정보, 특정 이벤트와 같은 정보들을 저장하며, 저장된 데이터를 통해 분석 및 보고에 활용하며, 널리 사용되는 데이터 저장소는 파일 스토리지와 데이터베이스 정도가 있습니다. 파일 스토리지의 경우, 데이터를 파일에 저장하여 개인용 컴퓨터의 하드 디스크에 있는 로컬 파일 시스템과 USB드라이브와 같은 이동식 미디어 또는 공유 파일 스토리지 시스템에 해당 파일을 정하는 형태를 취합니다. 일반적인 파일 형식으로는 CSV와 같은 구분된 텍스트 파일, JSON(JavaScript Object Notation), XML(eXtensible Markup Language), BLOB(Binary Large Object)가 있습니다. 다만 정형데이터와 반정형 데이터를 사람이 읽기 쉬운 형태로 저장하면 유용하기는 하지만 공간 및 처리에 있어서 최적화되지 않기에 이를 보완하고자 압축, 인덱싱, 효율적인 저장 및 처리를 지원하는 Avro, ORC, Parquet등의 최적화된 파일 형식으로 변환하여 사용하는 방식을 취하기도 합니다. 데이터베이스는 데이터를 저장하고 쿼리할 수 있는 중앙 시스템을 정의하는데 사용되며, 사실 파일 시스템도 일종의 데이터베이스라고 할 수 있습니다. 여기서 지칭하는 데이터베이스는 파일이 아닌 데이터 레코드를 관리하는 전용 시스템이라고 이해하면 되며, 크게 2가지로 나누어 볼 수 있습니다.
1. 관계형 데이터베이스
: 관계형 데이터 베이스는 정형 데이터를 저장하고 쿼리하는데 사용되며, 엔터티를 나타내는 테이블에 데이터를 저장하여 기본키를 통해 인스턴스를 참조합니다. 이와 같은 관계형 데이터베이스를 관리하는 시스템으로는 Oracle DMBS, Microsoft의 MS SQL Server, MySQL등이 있습니다.
2. 비관계형 데이터베이스
: 비 관계형 데이터베이스는 관계형 스키마를 적용하지 않는 데이터관리시스템으로 NoSQL 데이터베이스라고 지칭되기도 하지만 일부는 SQL언어의 변형을 지원하기도 하며, 키-값 DB, 문서 DB, 열 패밀리 DB, 그래프 DB등이 이에 해당됩니다.

이와 같이 저장한 데이터를 활용하여 조직은 분석을 진행하며, 대부분 아래와 같은 공통적인 아키텍처를 따릅니다.
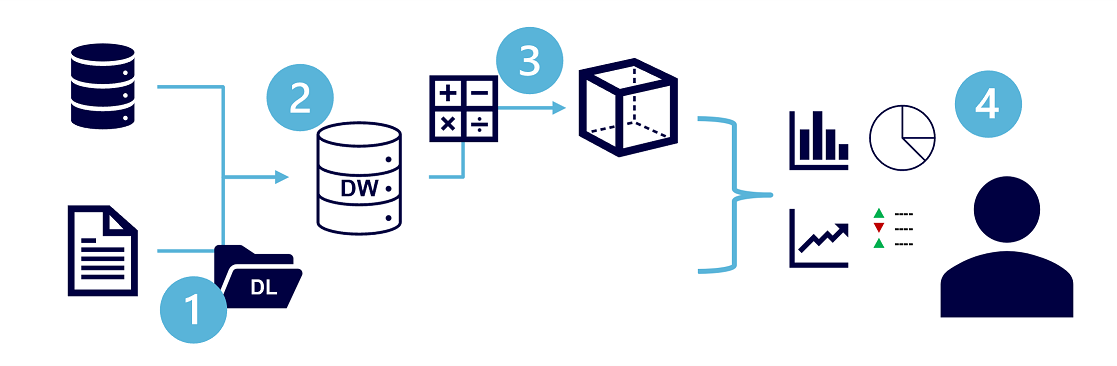
1. 데이터 파일을 분석을 위해 중앙 데이터 레이크에 저장
2. ETL(또는 ELT)프로세스가 파일 및 OLTP(Online Transaction Processing) DB에서 읽기 작업에 최적화된 데이터 웨어하우스로 데이터를 복사
3. 데이터 웨어하우스에서 데이터를 집계하여 OLAP(Online Analytical Processing)모델에 로드
4. 데이터 레이크, 데이터 웨어하우스 및 분석 모델의 데이터를 쿼리하여 시각화 및 대시보드 생성
- 데이터 레이크 : 대량의 파일 기반 데이터가 수집되어 분석되는 곳
- 데이터 웨어하우스 : 최적화된 관계형 스키마에 데이터를 저장하는 곳(일정한 형식으로 데이터 저장)
이상으로 데이터 형식부터 분석에 대한 내용에 대해 알아보았습니다. 데이터 분석에 관심이 있다면 데이터 형식과 분석 아키텍처에 대한 부분에 대해서 좀 더 깊게 공부해보는 것도 좋을 것 같습니다.
P.S 더 나은 개발자가 되기위해 공부중입니다. 잘못된 부분을 댓글로 남겨주시면 학습하는데 큰 도움이 될 거 같습니다.
'IT & 데이터 사이언스 > 이론 & 개념' 카테고리의 다른 글
| [Cloud] 데이터 엔지니어와 클라우드 (0) | 2022.05.30 |
|---|---|
| [Cloud] Azure Data Factory에 대하여 (0) | 2022.05.30 |
| [Cloud] Azure란? (0) | 2022.05.26 |
| [개념 설명] BI란? (0) | 2022.05.25 |
| [개념 설명] 클라우드 컴퓨팅이란? (0) | 2022.05.25 |




댓글