안녕하세요. 바른 호랑이입니다.
이번 게시글에서는 OpenAPI를 활용하여 데이터를 호출하고 적재하는 방법과 공공데이터 포털의 데이터가 필요할 때 활용하기 좋은 Python Library도 알아볼 예정입니다.
API(Application Programming Interface)란 컴퓨터나 컴퓨터 프로그램 사이의 연결을 지칭하는 용어로 일종의 다리역할을 한다라고 생각하면 됩니다. 그 중에서도 OpenAPI란 하나의 웹 사이트에서 자신이 가진 기능을 이용할 수 있도록 공개한 프로그래밍 인터페이스로 누구나 사용이 가능하기에 이를 응용하여 앱, 웹 등의 개발을 진행하거나 데이터 분석시 사용할 수 있습니다. 이를 조금 더 쉽게 접근하고 이용할 수 있게 대한민국 정부에서는 공공데이터 포털을 통해 여러 OpenAPI를 운영하고 있으며, 이번에는 이를 활용해볼 예정입니다. 단순히 API를 활용하여 데이터를 호출한 다음 데이터프레임으로 구축하는 것은 Colab환경에서 진행하였으며, 이를 로컬 DB에 적재하는 것은 로컬 PC에 Python, VSCode, jupyter Notebook을 설치 후 진행하였으니 참고바랍니다.
먼저 알아볼 것은 공공데이터 포털의 API를 활용하여 데이터 추출 후 데이터 프레임화하는 방법입니다. 실습을 위해 사용한 데이터는 행정안전부_행정표준코드_법정동코드이며, 각각의 API마다 호출방법 및 가공 방법은 다를 수 있으니 참고하시기 바랍니다.
※ 공공데이터 포털 API를 활용한 데이터 호출 및 적재방법



1. 공공데이터 포털 API를 이용하기 위해 회원가입 후 로그인을 합니다.
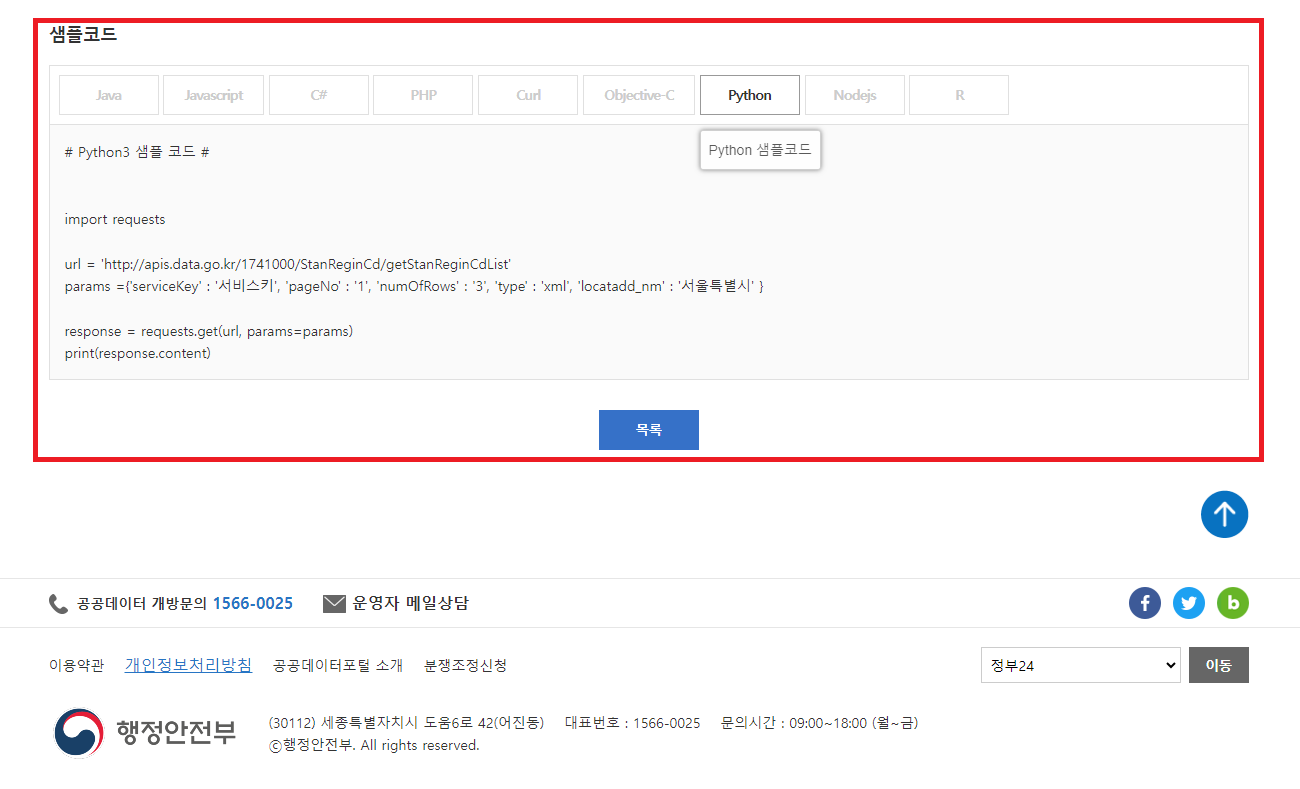
2. 원하는 API를 검색하여 찾은 후 샘플코드를 확인합니다.
3. 활용신청 버튼을 누른 후 활용신청양식에 맞게 내용을 작성한 후 신청을 합니다.
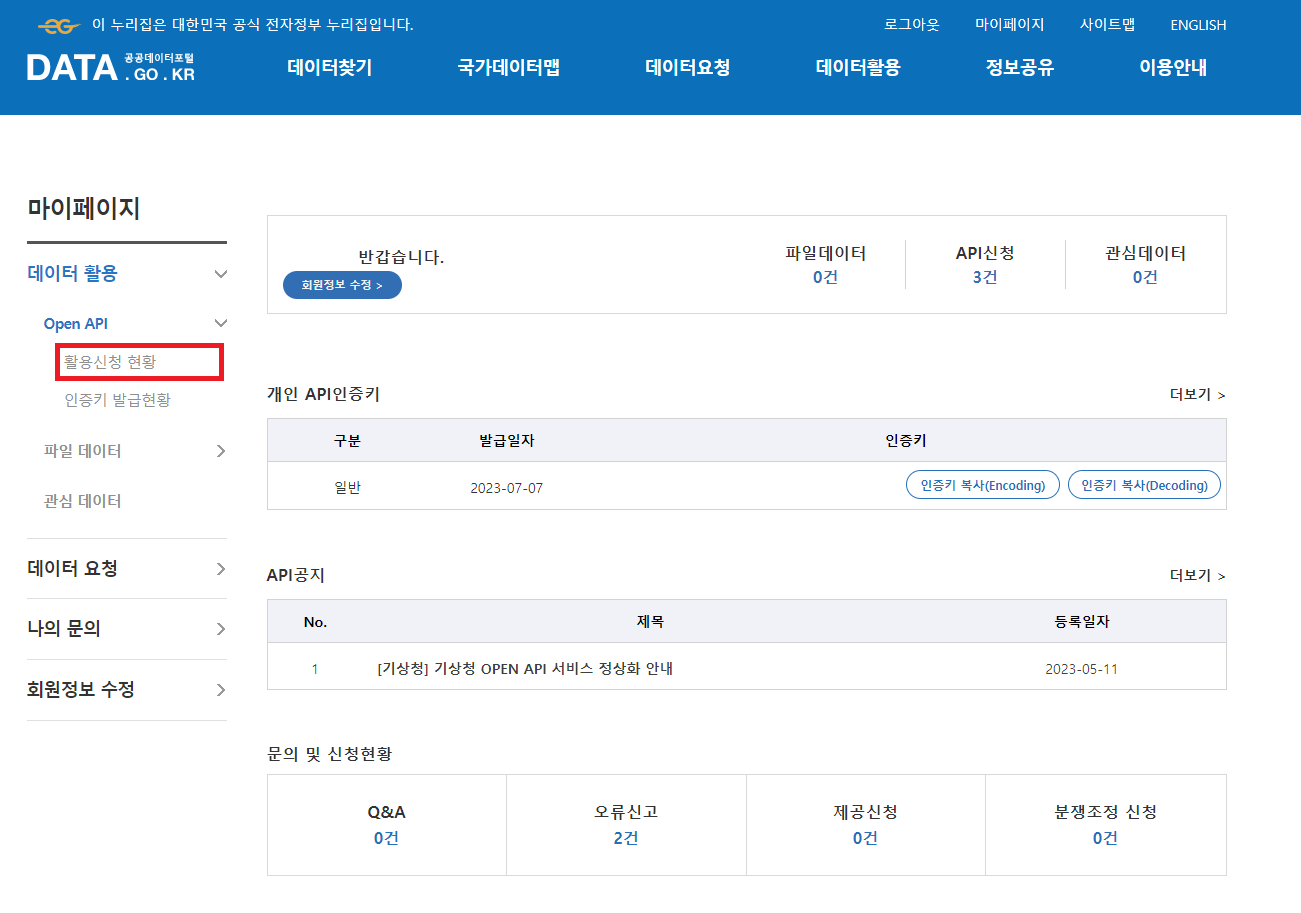
4. 승인이 완료되면 마이페이지-데이터활용-Open API-활용신청 현황으로 들어가 필요한 API를 찾아 클릭합니다.
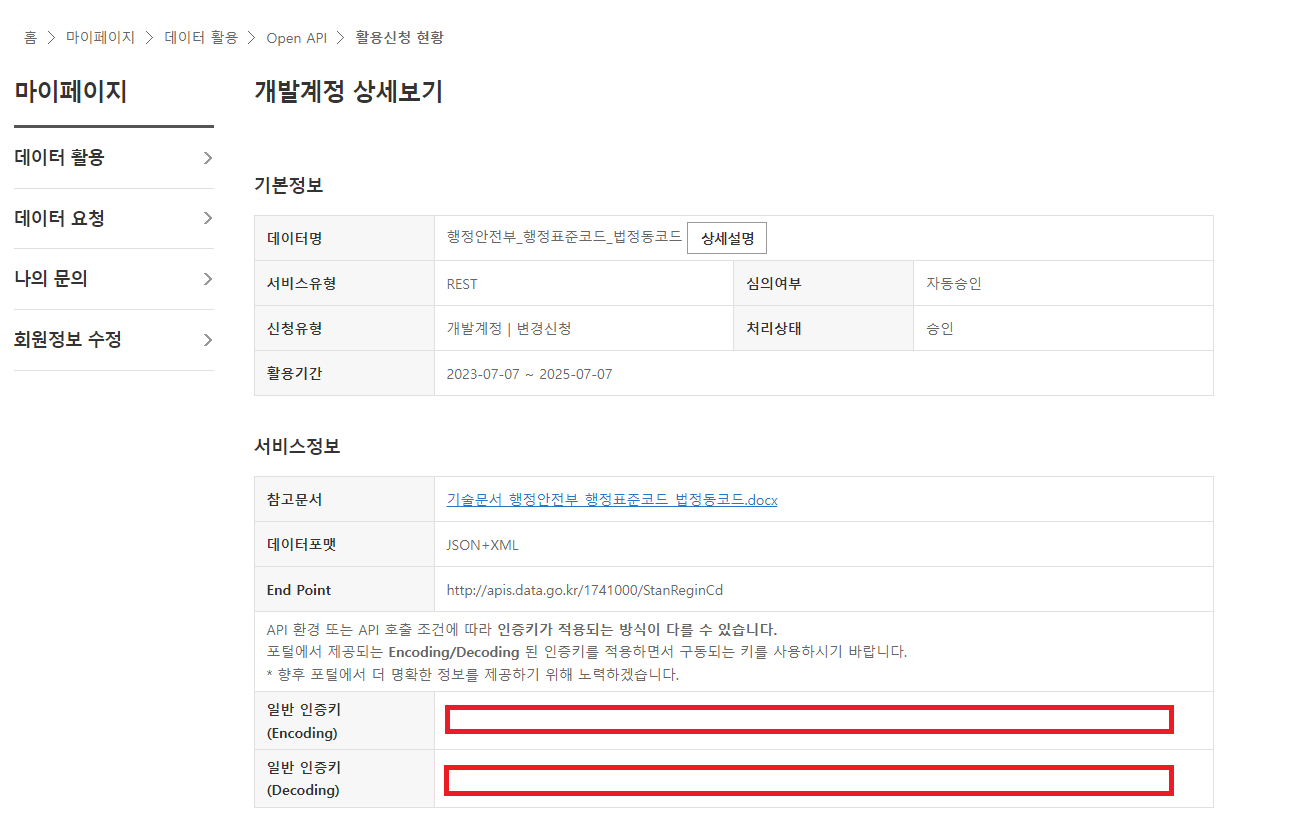
5. 개발계정 상세보기에서 인증키를 확인 후 저장합니다.
import pandas as pd
import requests
import json
# 전체 주소정보 추출용도로만 작성
# 1줄의 데이터를 호출하여 전체 로우수 확인 - 한 페이지의 최대 로우수는 1000로 확인 / 총 로우수를 1000으로 나눈 몫+1로 총 페이지 개수 계산
url = 'http://apis.data.go.kr/1741000/StanReginCd/getStanReginCdList'
first_params ={'serviceKey' : servicekey, 'pageNo' : '1', 'numOfRows' : '1', 'type' : 'json', 'locatadd_nm' : '' }
first_response = requests.get(url, params=first_params)
length = json.loads(first_response.content.decode('utf-8'))['StanReginCd'][0]['head'][0]['totalCount']
max_page_count = (length // 1000) + 1
df_values = []
df_columns = list(json.loads(first_response.content.decode('utf-8'))['StanReginCd'][1]['row'][0].keys())
for i in range(1, max_page_count+1):
pageNo = i
if i == max_page_count:
numOfRows = length % 1000
else:
numOfRows = 1000
cp = 0
while cp >= 0:
try:
params ={'serviceKey' : servicekey, 'pageNo' : pageNo, 'numOfRows' : numOfRows, 'type' : 'json', 'locatadd_nm' : '' }
response = requests.get(url, params=params)
stg_respones = json.loads(response.content.decode('utf-8'))['StanReginCd'][1]['row']
cp = -1
except:
cp += 1
if cp == 5:
print('Error가 발생하였습니다.')
break;
for data in stg_respones:
stg_list = list(data.values())
df_values.append(stg_list)
pd.DataFrame(df_values, columns=df_columns)6. 인증키를 활용하여 데이터를 호출한 후 Pandas 패키지를 활용하여 데이터 프레임화를 할 수 있게 코드를 작성 후 실행합니다.
공공데이터포털은 API를 통해 데이터를 제공할 시에 일반적으로 xml, json을 통해 제공하며, json을 통해 전달받은 데이터는 python에 존재하는 json 라이브러리를 활용하여 가공할 수 있습니다. 기본적인 가공은 위와 같이 진행하시며 되며, 그 이후에는 입맛에 따라 추가 가공 후 사용하시면 됩니다.
이와 같은 내용이 너무 복잡하다 하시면 법정동, 행정동 코드와 같은 공공데이터들의 일부를 간단하게 사용할 수 있게 만들어진 PublicDataReader라는 라이브러리가 있습니다. 라이브러리 안에 필요한 데이터가 있는 경우 이를 활용하여 간단하게 가공된 데이터를 얻을 수도 있으며, 세부적인 이용방법은 개발자분께서 github를 통해 공개하고 있으니 궁금하신 분들은 아래의 github주소를 참고하여 사용하시면 되겠습니다. 간단하게 Colab에서 이 라이브러리를 사용하면 아래와 같은 결과를 얻으실 수 있습니다.
※ PublicDataReader
GitHub - WooilJeong/PublicDataReader: 공공 데이터 조회를 위한 오픈소스 파이썬 라이브러리
공공 데이터 조회를 위한 오픈소스 파이썬 라이브러리. Contribute to WooilJeong/PublicDataReader development by creating an account on GitHub.
github.com
※ 간단한 사용법
# 라이브러리 이용 방법
# 필요 패키지 설치
!pip install PublicDataReader
import PublicDataReader as pdr
pdr.code_hdong() # 행정동
pdr.code_bdong() #법정동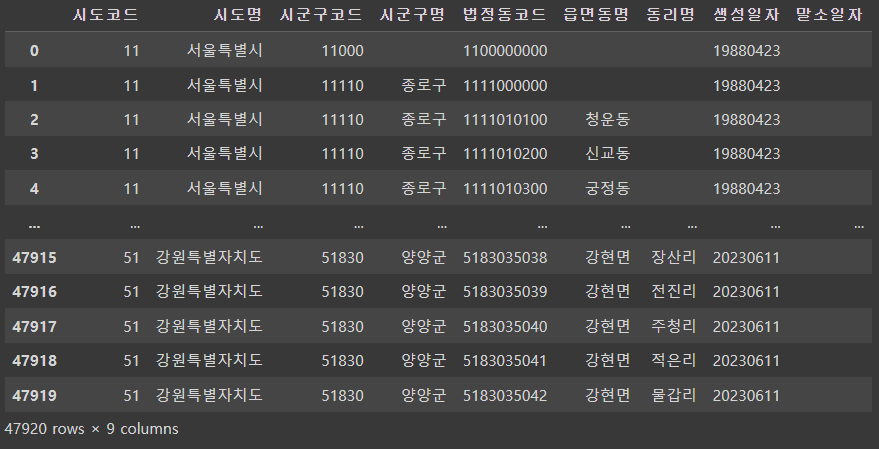
위와 같이 API를 통해 데이터를 호출하실 수 있으시다면 이를 통해 필요한 정보를 일정한 주기를 두고 호출 후 DB에 적재하는 것이 가능합니다. 다만 API를 제공하는 주체에 따라 일일 트래픽 허용량과 같은 제한지점이 있을 수 있으니 이를 실제 서비스에 접목시키기 전에 데이터를 제공해주는 주체쪽에서 제공하는 문서를 참고하는 것이 필요합니다. 이번에는 실 서비스에 들어가는 부분은 아니기에 이 부분은 각설하고 진행하였으며, API와 데이터는 한국수출입은행에서 일일단위로 제공중인 환율정보를 활용하였습니다. DB는 로컬 PC환경의 Db2를 활용하여 진행하였고, Db2 설치가 궁금하신 분들은 아래의 설치 관련 게시글을 참고하시기 바랍니다.
※ IBM DB2 설치
[환경설정] IBM DB2 설치
안녕하세요. 바른 호랑이입니다. 이번 게시글에서는 대표적인 DB중 하나인 IBM의 Db2 설치에 대해서 알아볼 예정입니다. 설치는 무료로도 이용이 가능한 IBM Db2 Community Edition을 설치할 예정이며, 설
data-is-power.tistory.com
※ OpenAPI를 활용하여 데이터 호출, 가공, 적재 후 일정주기에 따라 DB에 적재하는 방법

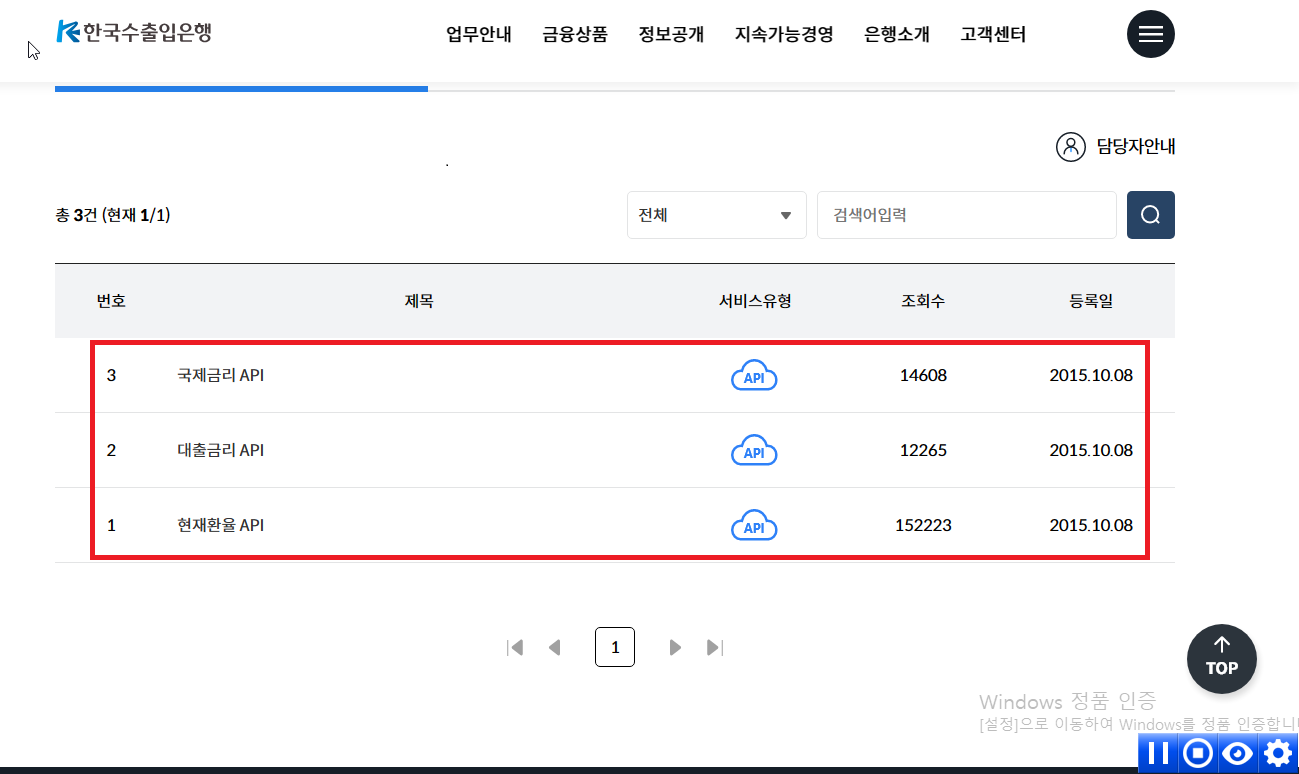




1. 한국 수출입은행이 제공하는 API관련 페이지에 접속합니다.
2. 사용을 원하는 API관련 게시글을 클릭하고 인증키 발급신청을 클릭합니다.
3. 본인인증 후 인증키를 신청합니다.
4. 발급받은 인증키를 저장합니다.
# 한국 수출입은행 api 호출 테스트
import requests
import pandas as pd
import json
from datetime import datetime, timedelta
# 수동 입력시 날짜 지정 후 넣기
'''
start_date = datetime(2022, 1 ,1)
end_date = datetime(2022, 1, 5)
'''
# start_date, end_date default 값
start_date = datetime.now()
end_date = datetime.now()
date_list = []
current_date = start_date
while current_date <= end_date:
date_list.append(current_date.strftime('%Y%m%d'))
current_date += timedelta(days=1)
authentication_key = '인증키'
url = 'https://www.koreaexim.go.kr/site/program/financial/exchangeJSON'
# 적재용 데이터 프레임 구조 구축용 호출
first_params = {'authkey' : authentication_key, 'searchdate' : '20230711', 'data' : 'AP01'}
first_response = requests.get(url, params=first_params)
df = pd.DataFrame(columns=list(json.loads(first_response.content)[0].keys()) + ['std_dt', 'crt_dt'])
for target_date in date_list:
searchdate = target_date
params = {'authkey' : authentication_key, 'searchdate' : searchdate, 'data' : 'AP01'}
response = requests.get(url, params=params)
try:
df_values = []
df_columns = list(json.loads(response.content)[0].keys()) + ['std_dt', 'crt_dt']
stg_responses = json.loads(response.content)
for stg_response in stg_responses:
stg_list = list(stg_response.values()) + [f'{target_date[:4]}-{target_date[4:6]}-{target_date[6:8]}', datetime.now().strftime('%Y-%m-%d')]
df_values.append(stg_list)
stg_df = pd.DataFrame(df_values, columns=df_columns)
df = pd.concat([df, stg_df])
except:
pass
df.reset_index(drop=True, inplace=True)
import pyodbc
# 접속 필요정보 구성(Driver는 사전에 다운로드 후 설치 필요)
driver = 'IBM DB2 ODBC DRIVER' # DB에 다른 Driver
host = 'Host이름'
port = 포트번호
database = 'DB명'
user = 'DB유저이름'
password = 'DB유저 비밀번호'
# DB연결
conn = pyodbc.connect(f'DRIVER={driver};HOSTNAME={host};PORT={port};PROTOCOL=TCPIP;DATABASE={database};UID={user};PWD={password}')
# DataFrame값 넣기
try:
cursor = conn.cursor()
for index, row in df.iterrows():
cursor.execute(
"INSERT INTO CUR.EXCHANGE_RATE (result, cur_unit, ttb, tts, deal_bas_r, bkpr, yy_efee_r, ten_dd_efee_r, kftc_bkpr, kftc_deal_bas_r, cur_nm, std_dt, crt_dt) "
f"VALUES ({row.result}, '{row.cur_unit}', {row.ttb.replace(',', '')}, {row.tts.replace(',', '')}, {row.deal_bas_r.replace(',', '')}, {row.bkpr.replace(',', '')}, {row.yy_efee_r.replace(',', '')}, {row.ten_dd_efee_r.replace(',', '')}, {row.kftc_bkpr.replace(',', '')}, {row.kftc_deal_bas_r.replace(',', '')}, '{row.cur_nm}', '{row.std_dt}', '{row.crt_dt}')"
)
conn.commit()
except pyodbc.Error as e:
print(f'오류발생: {e}')
finally:
conn.close()5. 발급받은 인증키와 Python 라이브러리를 활용하여 데이터 프레임화를 하고 DB에 연결한 후 DB에 생성해놓은 테이블에 데이터를 적재하는 python파일을 만듭니다.(설치 필요 패키지 : Pandas, Requests, Pyodbc)


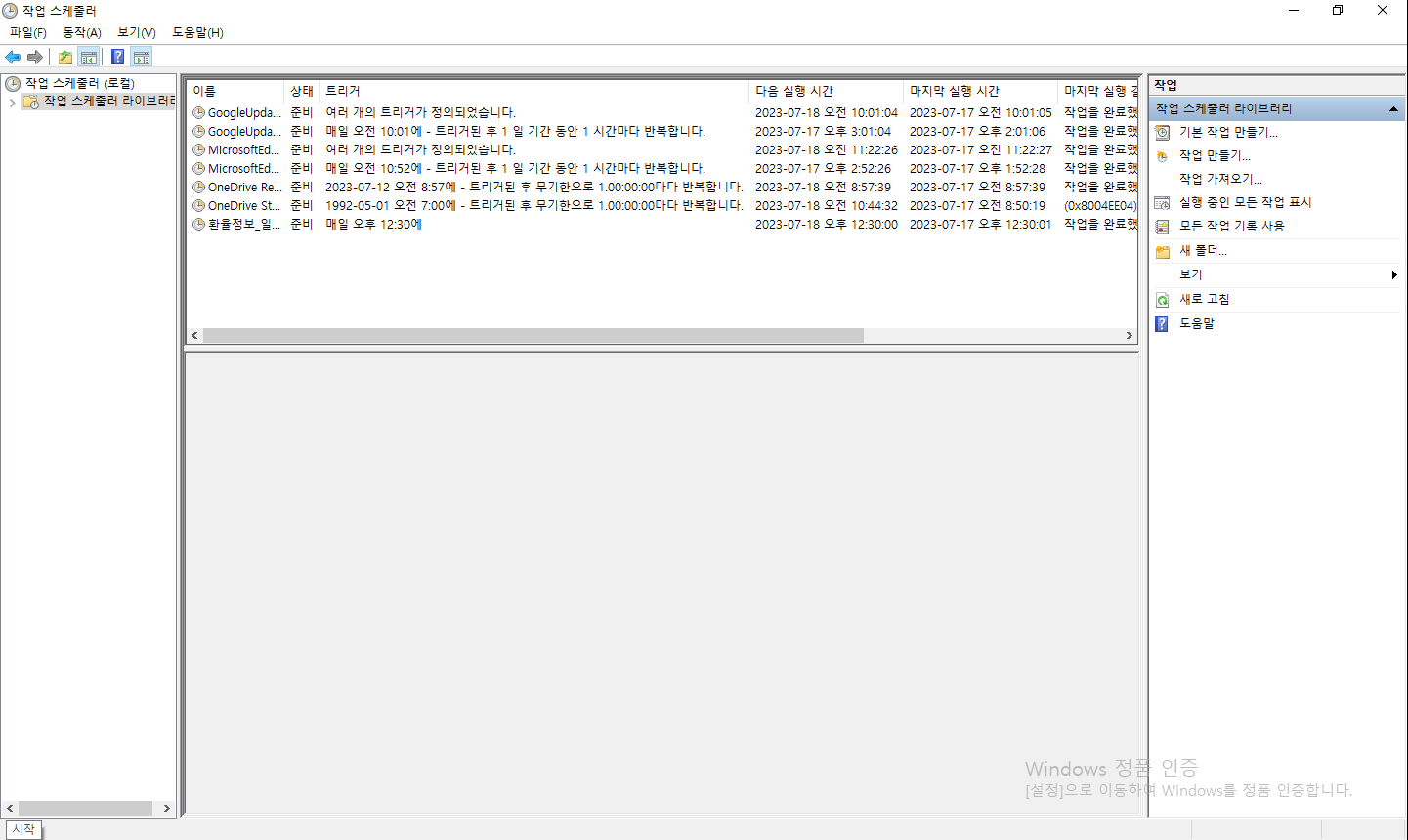

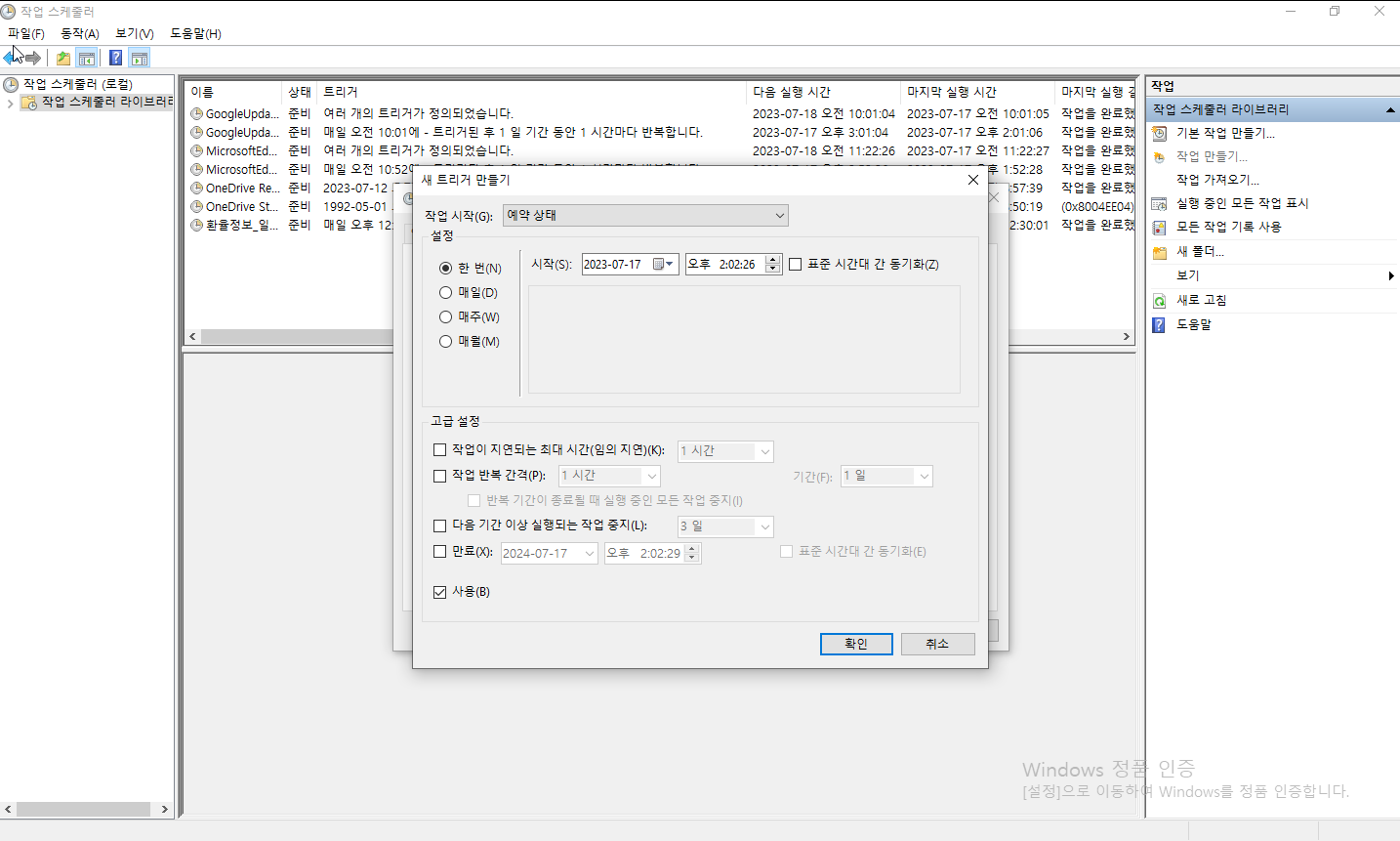



6. 해당 python파일을 실행시킬 수 있는 cmd 명령어문을 txt파일로 작성 후 bat파일로 강제 형변환합니다.
7. Windows작업 스케줄러를 실행시킨 후 해당 bat파일을 실행시킬 수 있는 스케줄을 작성 후 저장합니다.
위와 같은 과정을 통해 진행하면 API를 통해 호출한 데이터를 데이터 프레임으로 가공한 후 DB에 적재할 수 있습니다. 이상으로 OpenAPI를 활용한 데이터 호출&적재에 대해 알아보았습니다.
P.S 더 나은 개발자가 되기위해 공부중입니다. 잘못된 부분을 댓글로 남겨주시면 학습하는데 큰 도움이 될 거 같습니다
'IT & 데이터 사이언스 > Python' 카테고리의 다른 글
| [Python] Python의 자료형(숫자, 문자열, 리스트)⑴ (2) | 2024.04.18 |
|---|---|
| [Python] Python이란? (2) | 2024.04.18 |
| [Python Data Analytics] Python을 활용한 Machine Learning (0) | 2023.06.23 |
| [Python Data Analytics] Python을 활용한 데이터 전처리(2) (0) | 2023.06.20 |
| [Python Data Analytics] Python을 활용한 데이터 전처리(1) (0) | 2023.06.19 |




댓글