※ MSSQL 및 SSMS 설치
[환경설정 / MSSQL] MSSQL 및 SSMS 설치
※ MSSQL이란? [SQL / MSSQL] MSSQL이란? 안녕하세요. 바른호랑이입니다. 이번 게시물에서는 MSSQL에 대해서 설명드릴 예정입니다. MSSQL은 Microsoft SQL Server의 약어로 관계형 데이터베이스 관리시스템(RDBMS)
data-is-power.tistory.com
안녕하세요. 바른 호랑이입니다.
이번 게시글에서는 MSSQL을 활용하여 데이터 분석작업을 진행할 때 유용하게 쓸 수 있는 몇가지 쿼리문을 소개해드리려고 합니다. MSSQL 및 SSMS를 사용하였으며, 해당 프로그램에 대한 설치방법이 궁금하신 분들은 위의 게시글을 참조해주시기 바랍니다.
데이터의 규모가 억단위가 넘어가는 테이블을 다루는 거대한 조직에서는 테이블 전체를 조회하거나 전체 행의 수를 확인하기 위해 select * from 테이블명 처럼 쿼리를 작성하면 시간도 오래걸리고, 과부하 위험이 있습니다. 하지만 데이터 분석을 시작하기 위해서는 테이블에 대한 기본적인 정보들을 확인을 해야하기에 대략적인 테이블의 구조와 전체 행의 수는 확인을 해야합니다. 이때 사용할 수 있는 것들이 TOP 함수와 sysindexs 및 sysobjects이며, 해당 내용들에 대해 다뤄보려합니다. 이와 더불어 INFORMATION_SCHEMA를 활용하여 특정 테이블의 컬럼명을 확인하는 쿼리또한 소개해드리겠습니다.
1. TOP 함수
: 해당 쿼리는 소개해드릴 것이 없을 정도로 간단하며 TOP 숫자 * from 테이블명 형태로 작성가능하며, 따로 설명할만한 부분이 없으므로 자세한 사용법은 아래의 쿼리문과 사진을 참조해주시기 바랍니다.
select TOP 10 * from dbo.test01
select TOP 10 * from dbo.test02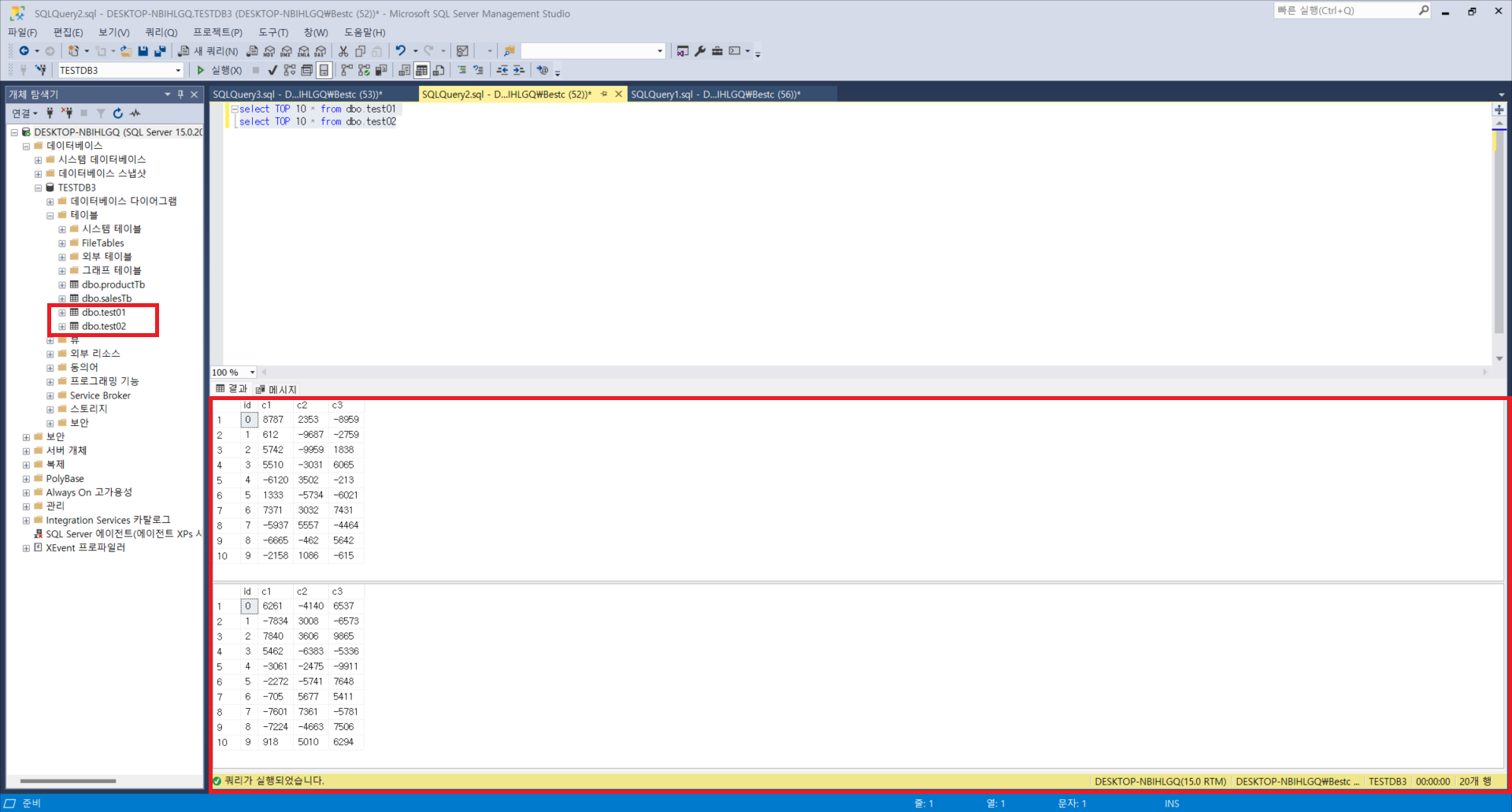
2. 테이블의 전체 행 수 확인(sysindexes와 sysobjects를 이용 / count 지양)
: 테이블의 전체 행수를 구하는 가장 간단한 방법은 count 함수를 사용하는 것입니다. 하지만 억단위 데이터로 넘어가면 시간이 굉장히 오래걸리기 때문에 좋은 쿼리문은 아니라고 할 수 있습니다. 이때 사용할 수 있는 것이 sysindexes와 sysobjects이며, 자세한 쿼리문들과 내용은 사진을 참고해주시기 바랍니다.
-- 가장 쉬운 방법 / COUNT : 오래걸리고 비효율적
select count(*) from dbo.test01
-- sysindexes와 sysobjects를 이용하는 방법_1
/* sysobject type컬럼의 의미
AF = Aggregate function (CLR) 집계함수
C = CHECK constraint 체크제약조건
D = DEFAULT (constraint or stand-alone) 디폴트 제약조건
F = FOREIGN KEY constraint 참조 제약조건
FN = SQL scalar function 함수
FS = Assembly (CLR) scalar-function 어셈블(CLR) SQL 스칼라함수
FT = Assembly (CLR) table-valued function 어셈블(CLR) SQL 테이블반환함수
IF = SQL inline table-valued function 인라인 테이블 반환함수
IT = Internal table 내부 테이블
P = SQL Stored Procedure 프로시져
PC = Assembly (CLR) stored-procedure 어셈블(CLR) 프로시져
PG = Plan guide 계획 지침
PK = PRIMARY KEY constraint 기본 키 제약조건
R = Rule (old-style, stand-alone) 룰 규칙
RF = Replication-filter-procedure 복제 필터 프로시저
S = System base table 시스템 기본테이블
SN = Synonym 동의어
SO = Sequence object 시퀀스 객체
U = Table (user-defined) 사용자 테이블
V = View 뷰
EC = Edge constraint 엣지 제약(그래프)
*/
select MAX(A.rows) from
( select * from sysindexes ) AS A
inner join
( select * from sysobjects ) AS B
on A.id = B.id
where B.type = N'U' and B.name = N'test01'
-- sysindexes와 sysobjects를 이용하는 방법_2
-- OBJECT_ID는 sysobjects의 name과 일치하는 테이블의 id값을 가져옴
select rows
from sysindexes
where indid < 2 -- indexid = 0 : 힙, indexid = 1 : 클러스터
and id = OBJECT_ID('dbo.test01');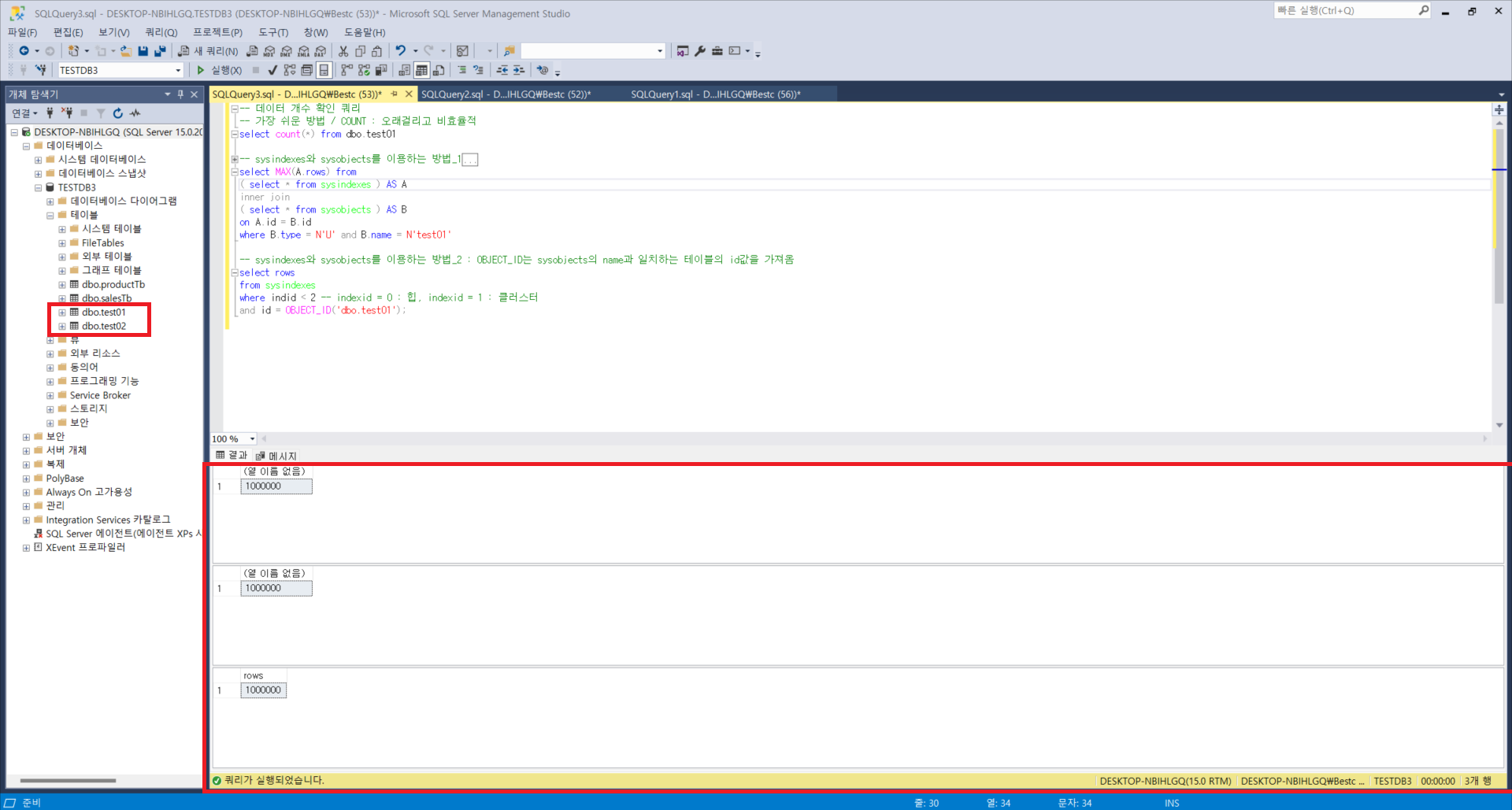
3. 테이블의 컬럼 이름 확인(INFORMATION_SCHEMA.COLUMNS 이용)
: 특정 테이블의 컬럼 이름이 무엇인지 알아야 할 때도 있고 2개의 테이블의 컬럼 이름의 일치여부를 확인해야할 상황이 있을 수도 있습니다. 이럴 때는 INFORMATION_SCHEMA.COLUMNS과 JOIN기능을 통해 손쉽게 해결할 수 있으며, 자세한 쿼리문과 내용은 사진을 참고해주시기 바랍니다.
-- 속성(컬럼)명 확인용 쿼리
select COLUMN_NAME
from INFORMATION_SCHEMA.COLUMNS
where TABLE_NAME = N'test01'
-- 2개의 테이블간 컬럼명 일치여부 확인
select * from
(
select COLUMN_NAME
from INFORMATION_SCHEMA.COLUMNS
where TABLE_NAME = N'test01'
) as T_001
full outer join
(
select COLUMN_NAME
from INFORMATION_SCHEMA.COLUMNS
where TABLE_NAME = N'test01'
) as T_002
on T_001.COLUMN_NAME = T_002.COLUMN_NAME
이상으로 데이터 분석시 유용한 쿼리문 몇가지에 대해 알아봤습니다.
P.S 더 나은 개발자가 되기위해 공부중입니다. 잘못된 부분을 댓글로 남겨주시면 학습하는데 큰 도움이 될 거 같습니다.
'직장생활 > Tips - 업무관련' 카테고리의 다른 글
| [Tips] SQL 스토어드 프로시저(Stored Procedure) 작성 요령 (2) | 2023.04.19 |
|---|---|
| [Tips] PowerShell을 활용한 파일 압축 및 해제 방법 (0) | 2022.09.18 |
| [Tips] Power BI 파일복구 및 복원 방법(+Tabular / pbi-tools) (0) | 2022.07.29 |



댓글