※ Azure Data Factory 사용방법(1) - Azure SQL Server / DB 생성방법
[클라우드 서비스 / Azure] Azure Data Factory 사용방법(1)
※ Microsoft docs Azure Data Factory 설명서 - Azure Data Factory 클라우드 데이터 통합 서비스인 Data Factory를 사용하여 자동화된 데이터 파이프라인에 데이터 스토리지, 이동 및 처리 서비스를 구성하는 방..
data-is-power.tistory.com
※ Azure Data Factory 사용방법(2)
[클라우드 서비스 / Azure] Azure Data Factory 사용방법(2)
※ Microsoft docs Azure Data Factory 설명서 - Azure Data Factory 클라우드 데이터 통합 서비스인 Data Factory를 사용하여 자동화된 데이터 파이프라인에 데이터 스토리지, 이동 및 처리 서비스를 구성하는 방..
data-is-power.tistory.com
※ RPA로 경우의 수 확인하기 - 웹사이트 크롤링 하는 방법
[MBTI_16Personality] RPA로 경우의 수 확인하기(1)
※ 심심해서 해보는 RPA관련 Toy_Project 최근들어 인간의 성격유형을 정리해놓은 MBTI에 관심이 생겨 관련 성격유형들에 대한 내용들을 읽다가 테스트 문항들의 조합에 따른 MBTI 결과가 어떻게 나오
data-is-power.tistory.com
안녕하세요. 바른 호랑이입니다.
이번 게시글에서는 크롤링을 통해 모은 데이터를 작업 스케줄러를 활용해서 DB에 적재하는 방법에 대해서 알아볼 예정입니다. 해당 사항을 진행하기 위해서는 DB가 필요하며, 저번에 만들었던 SQL Server와 SQL DB를 활용하여 진행하였음을 감안하고 보시면 되겠습니다. Azure SQL Server, DB 생성 방법 및 웹 크롤링에 대한 자세한 사항들이 궁금하신 분들은 위의 게시글들을 참조해주시기 바랍니다.
0. Azure SQL DB에 적재에 사용할 테이블 생성하기
- 데이터 적재를 위해서는 양식에 맞는 테이블을 사전에 SQL DB에 생성해야함.

1. 파이썬을 활용하여 웹 페이지 데이터 크롤링 후 Azure SQL DB에 적재하기
- 데이터를 크롤링 한 후 DB에 적재하는 과정을 알아보기 위해 한국무역협회에서 제공하는 환율정보를 활용
- 주요 사용 패키지 : Selenium(크롤링), Pandas(Data 정리 및 적재목적), pyodbc(SQL DB연결 및 적재목적)
- 구현방법 : Selenium을 활용하여 무역협회 사이트 접속 후 크롤링 Pandas로 정리하여 Pyodbc로 SQL에 적재
- 사전 필요정보 : Azure SQL 서버관련 정보들(서버이름, 관리자 이름, 비밀번호, DB이름), 적재용 테이블 생성
# 사용할 패키지 경로 지정
import sys
sys.path.append('C:\\Users\\Bestc\\anaconda3\\Lib\\site-packages')
# 필요 패키지 로드
# RPA
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
# Crawling
import pandas as pd
# 크롬 개발자 버전 에러 메세지 삭제
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-logging'])
# 한국무역협회 사이트 접속
URL = "https://www.kita.net/cmmrcInfo/ehgtGnrlzInfo/rltmEhgt.do"
driver = webdriver.Chrome('C:\\Workspace\\python\\Toy_Project_2022\\MBTI\\chrome\\chromedriver.exe', options = options)
driver.get(URL)
time.sleep(15) # 로딩시간에 맞게 적정히 수정
# 통화별 환율관련 수치 가공 후 리스트로 저장
import re
data_01 = driver.find_element(By.XPATH, f'//*[@id="contents"]/div[3]/div[2]').text
data_02 = re.sub('[^0-9a-zA-Z.\n ]', '', data_01)
data_03 = data_02.replace(',', '')
data_04 = data_03.replace(',', '')
data_05 = data_04.split("\n")[1:]
# 날짜 데이터 추출 후 리스트에 날짜 추가
date = driver.find_element(By.XPATH, f'//*[@id="contents"]/div[3]/div[1]/div[1]').text
date_01 = date.split('\n')
date_02 = date_01[0].replace('년', '-')
date_03 = date_02.replace('월', '-')
date_04 = date_03.replace('일', '')
time.sleep(5) # 로딩시간에 맞게 적정히 수정
driver.close()
# 데이터 프레임에 넣기
df_01 = pd.DataFrame({'Date' : [], 'Currency' : [],
'Exchange_rate' : [], 'Day_to_day' :[],
'Rise_and_fall' : [],
'Buy' : [], 'Sell' : [],
'To_Transfer' : [], 'Receive' : []})
for i in range(len(data_05)):
df_01.loc[len(df_01)] = [date_04] + data_05[i].split()
info = pd.read_csv("C:\Workspace\python\Toy_Project_2022\ADF_ETL\info\sqlinfo.txt", sep=":")
# SQL 서버연결 및 Pandas로 정리한 데이터 적재
import pyodbc
server = info.loc[0][0] + '.database.windows.net' # sql 서버 이름
database = info.loc[0][3] # sql db이름
username = info.loc[0][1] # sql 서버 관리자 ID
password = info.loc[0][2] # sql 서버 관리자 PW
cnxn = pyodbc.connect('DRIVER={SQL Server};SERVER='+server+';DATABASE='+database+';UID='+username+';PWD='+ password)
cursor = cnxn.cursor()
# Insert Dataframe into SQL Server:
for index, row in df_01.iterrows():
cursor.execute("INSERT INTO dbo.Exchange_rate_test (Date,Currency,Exchange_rate,Day_to_day,Rise_and_fall,Buy,Sell,To_Transfer,Receive) values(?,?,?,?,?,?,?,?,?)",
row.Date, row.Currency, row.Exchange_rate, row.Day_to_day, row.Rise_and_fall, row.Buy, row.Sell, row.To_Transfer, row.Receive)
cnxn.commit()
cursor.close()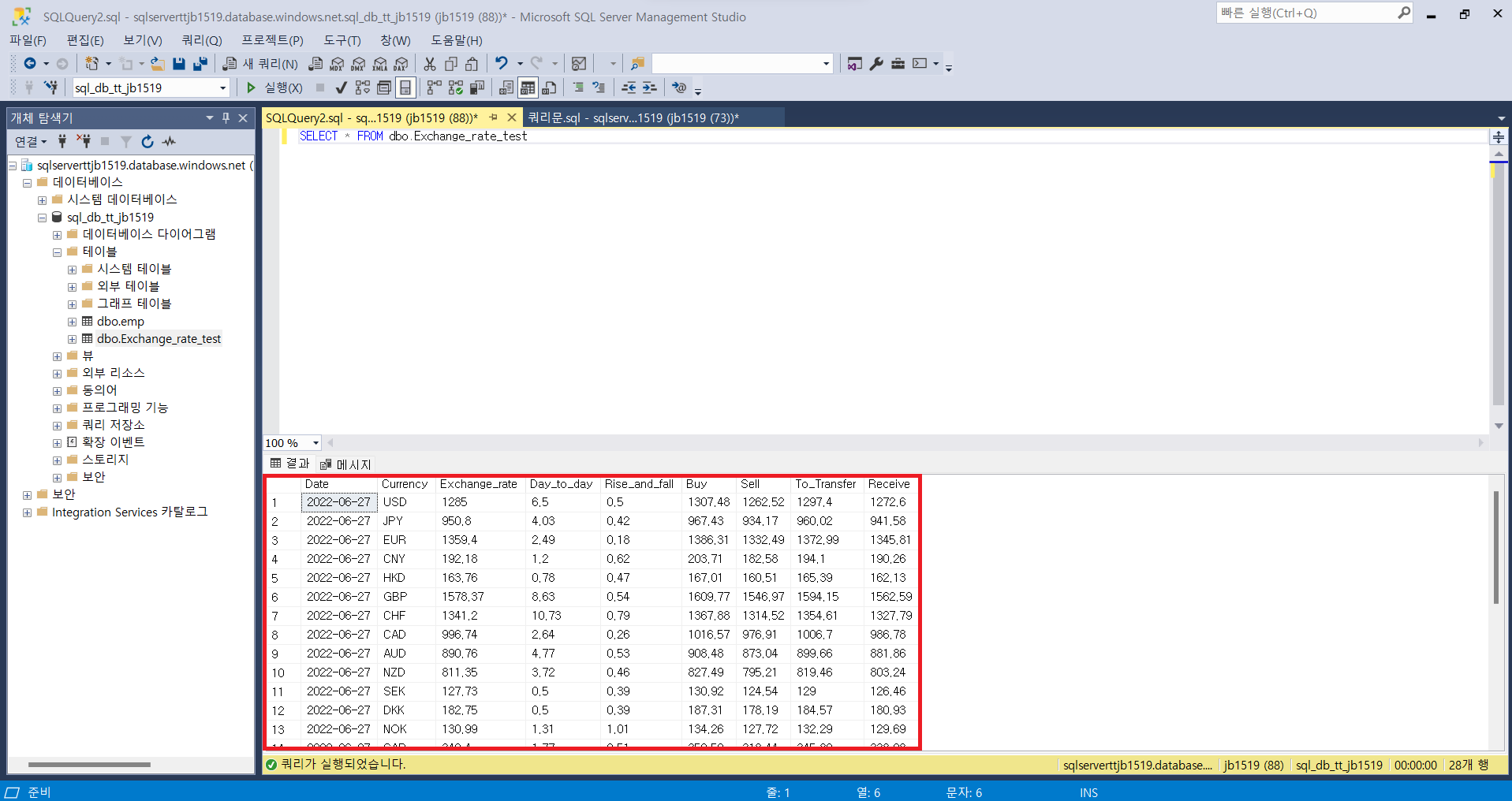
2. 작성한 파이썬 파일을 실행시킬 bat파일 생성 및 작업 스케줄러로 일일단위로 자동화하기
- bat파일은 CLI를 사용해야하나 사용 최소화를 위해 .py파일이 위치한 폴더 내에 작성
- bat파일 작성법 : 메모장에 명령문을 적은 후 강제 형변환 진행
(설정에서 파일 형식을 볼 수 있게하고 .txt를 .bat으로 변경)
- 작성한 명령문 : python ExchangeRate_Crawling.py
- 작업 스케줄러는 일일 단위 1회만 21:00에 매일 실행하도록 작성(트리거, 동작[스크립트 및 시작위치 작성])
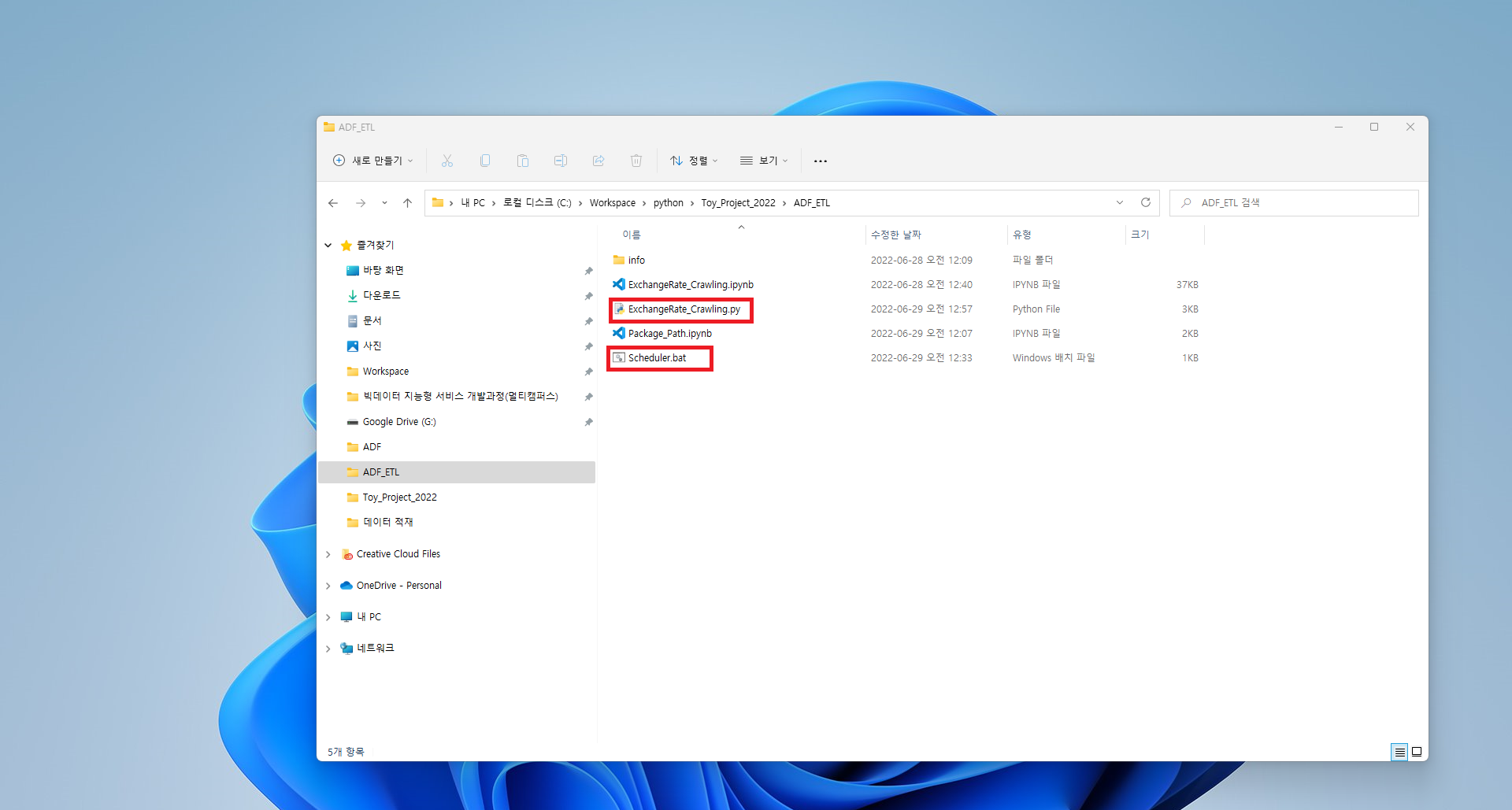
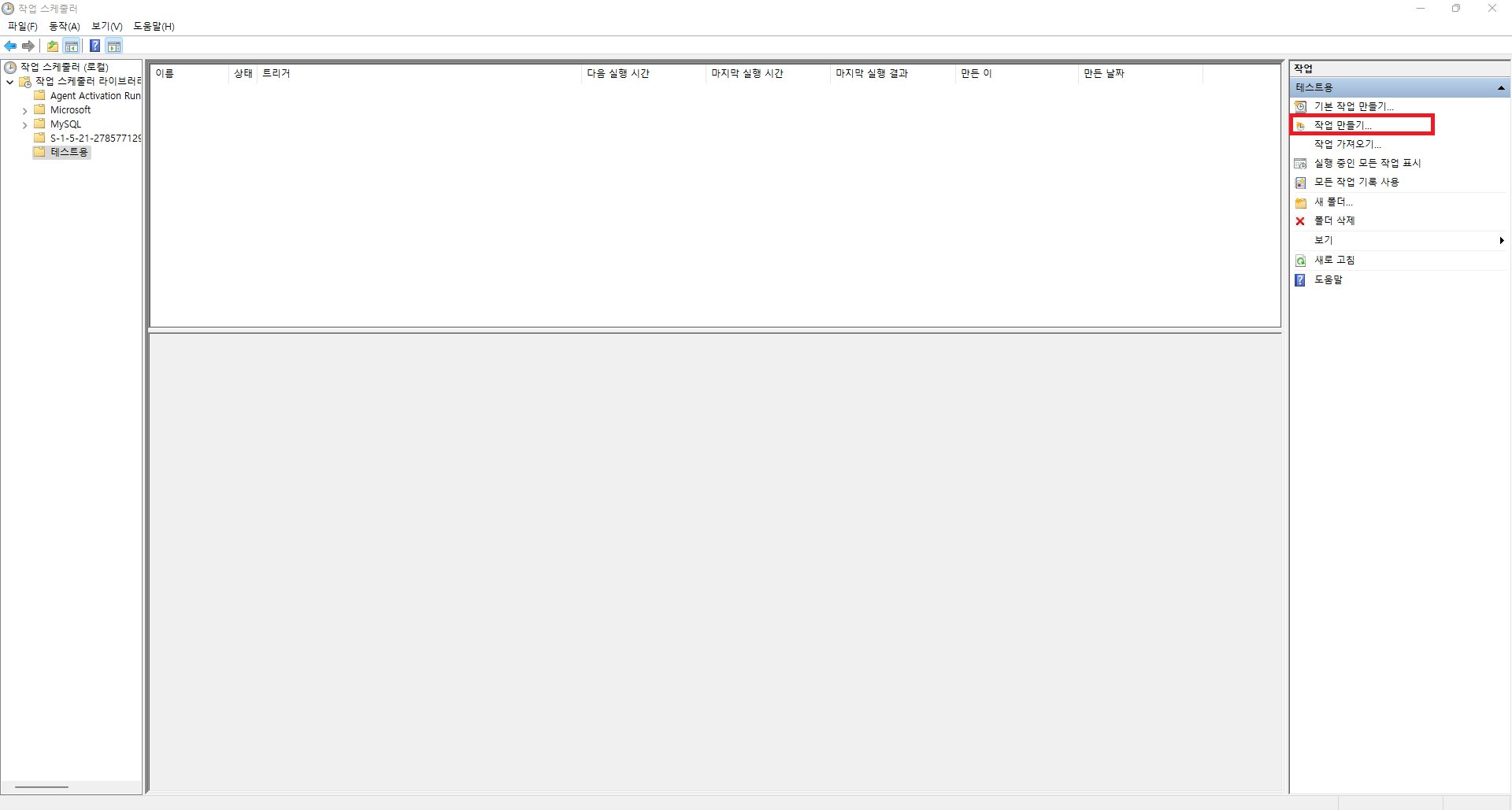
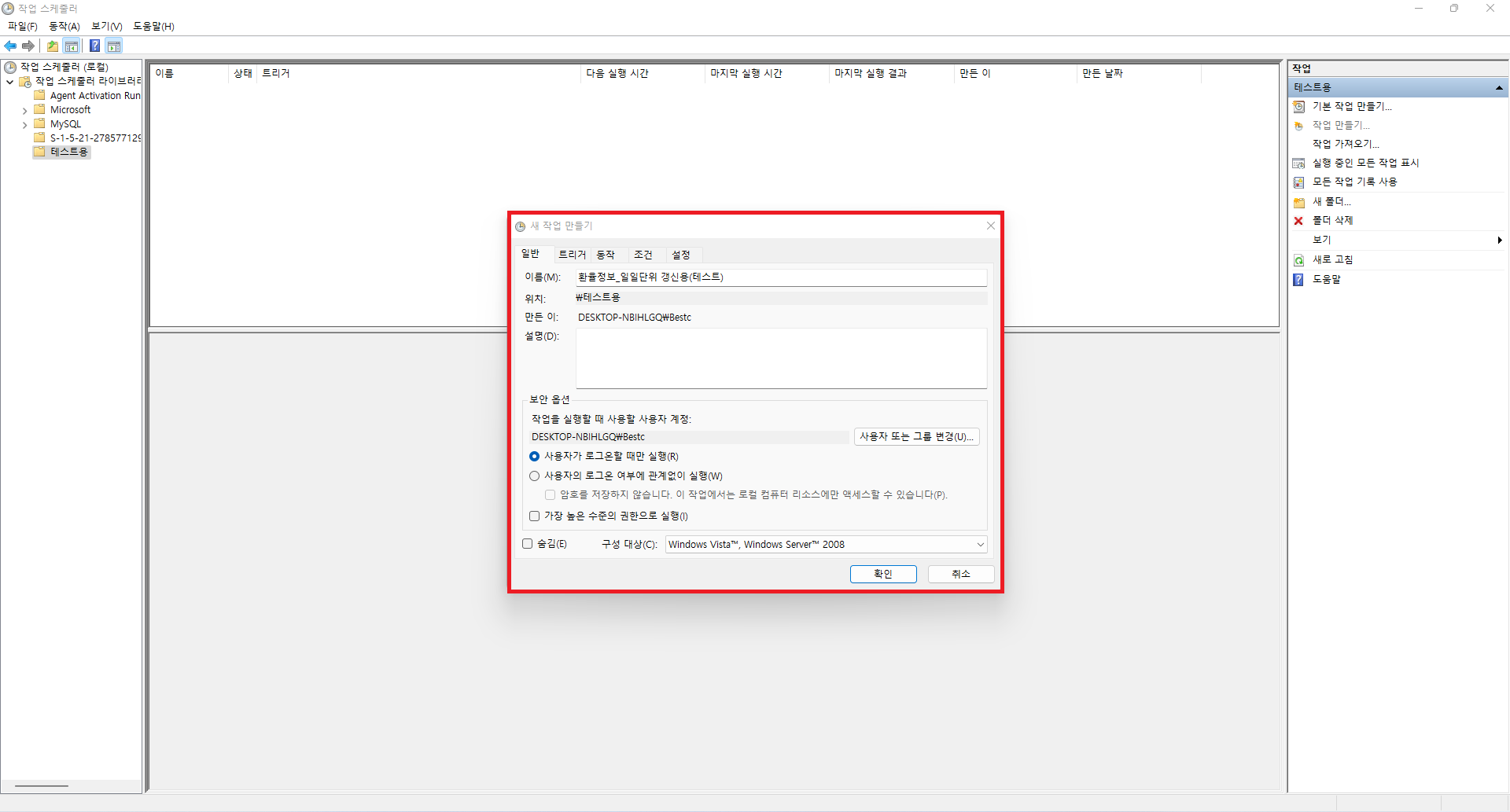
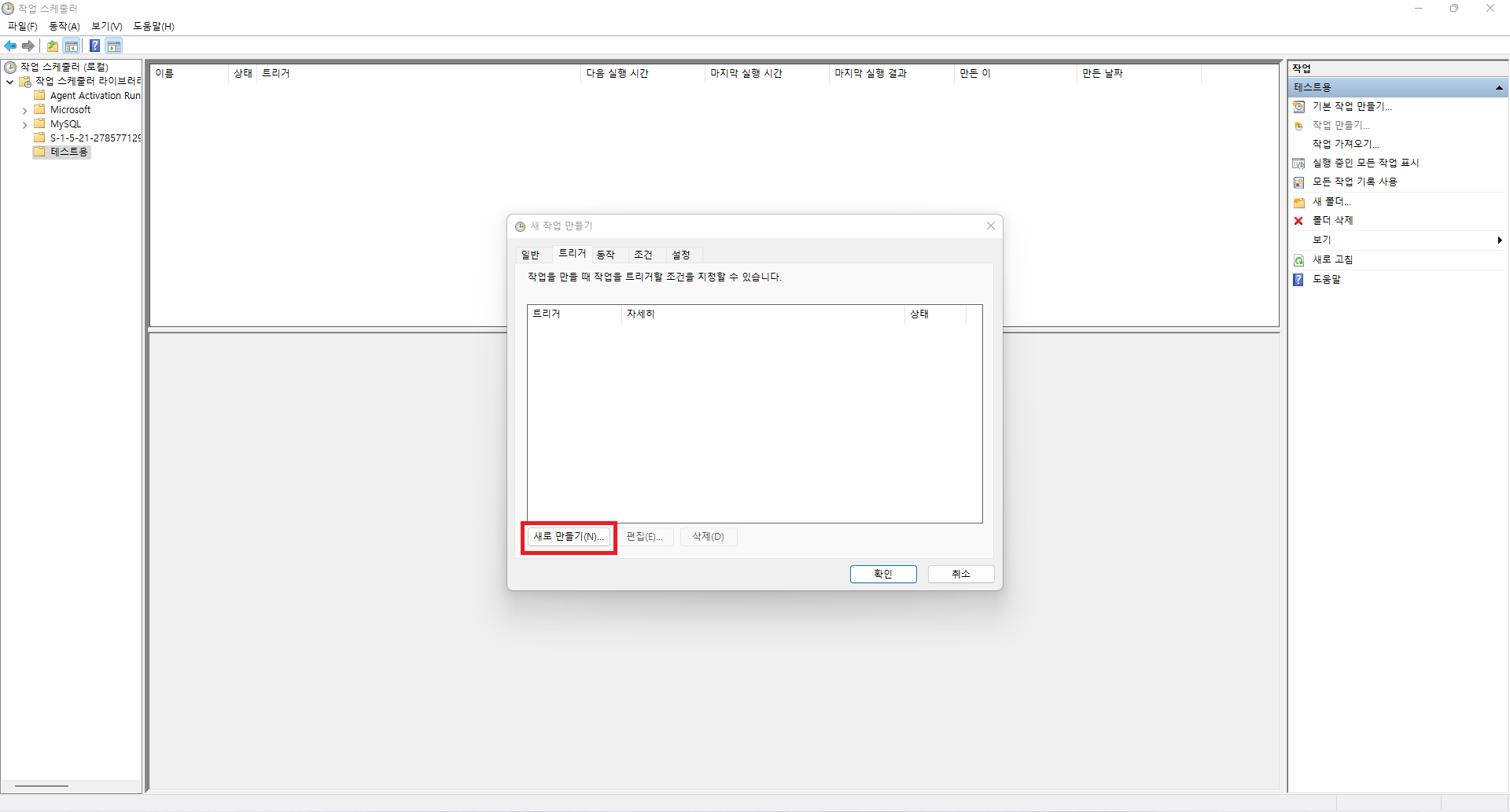
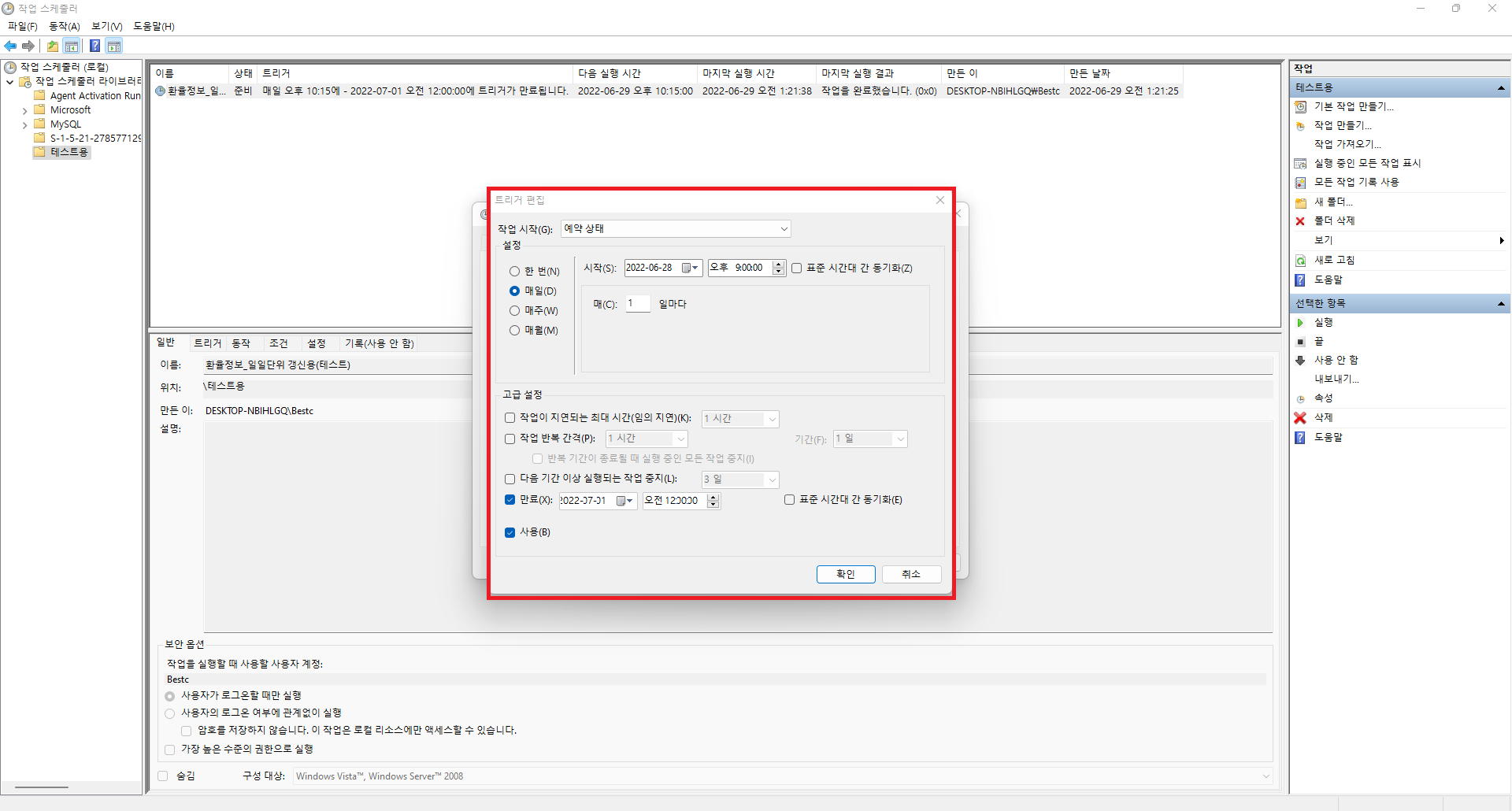


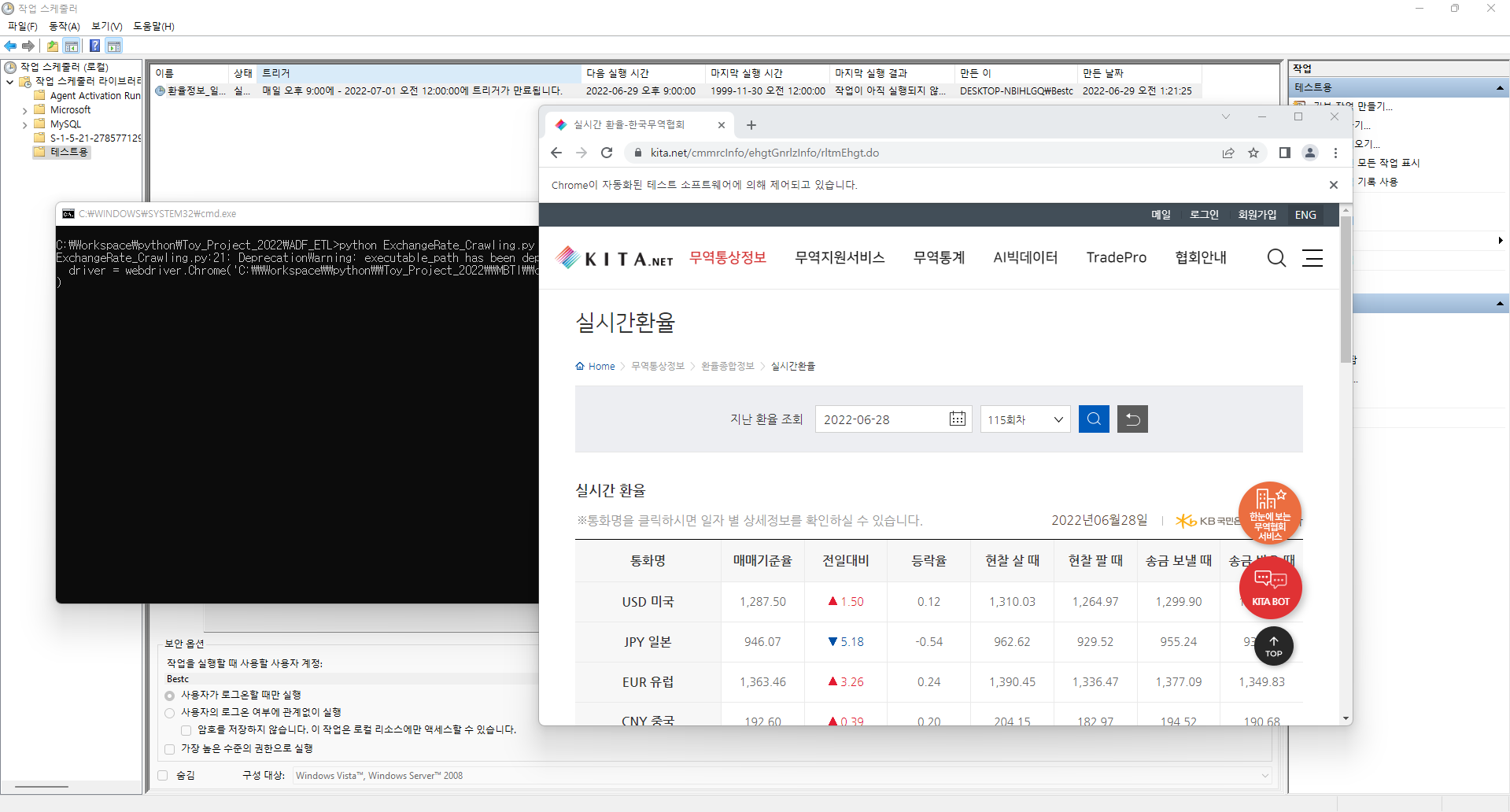
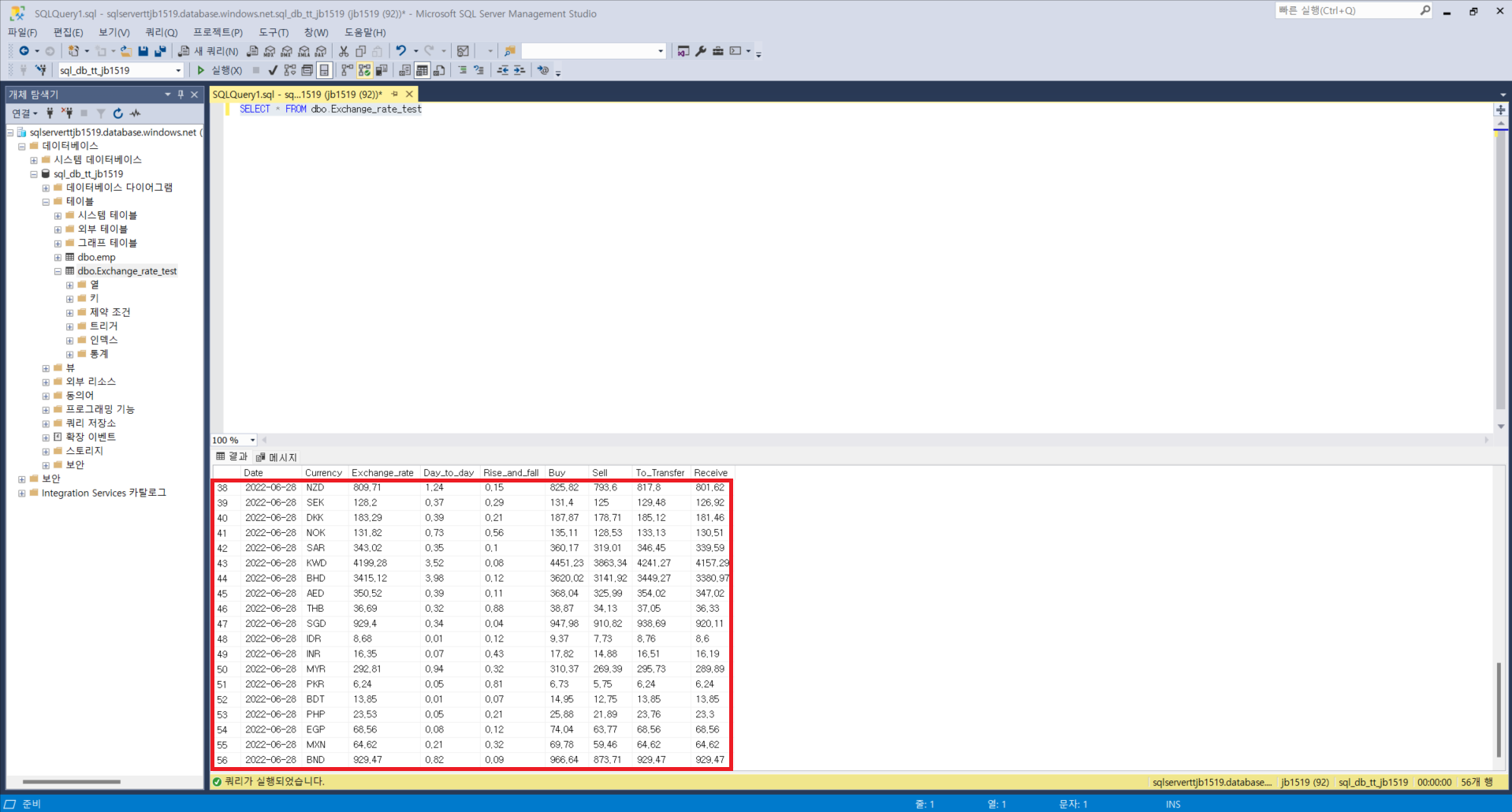
위와 같은 순서로 따라하시면 DB에 크롤링한 데이터를 일일단위 또는 정해진 주기로 적재하는 것이 가능합니다. 이렇게 적재한 데이터를 활용하여 Azure Data Factory를 통해 ETL과정을 수행할 수도 있으며, 데이터 분석을 통해 조직의 효율성을 높이는 것 또한 가능합니다. 데이터 분석 및 엔지니어링에 관심이 있으신 분들은 해당 방법들도 알아두시면 좋을 것 같습니다.
P.S 더 나은 개발자가 되기위해 공부중입니다. 잘못된 부분을 댓글로 남겨주시면 학습하는데 큰 도움이 될 거 같습니다.
세부코드가 궁금하신 분들은 아래 GitHub를 참고해주시기 바랍니다.
※ Github
GitHub - Jeong-Beom/Toy_Project_2022: 2022년도에 진행한 Toy_Project들에 대한 레파지토리입니다.
2022년도에 진행한 Toy_Project들에 대한 레파지토리입니다. Contribute to Jeong-Beom/Toy_Project_2022 development by creating an account on GitHub.
github.com
'IT & 데이터 사이언스 > 환경설정 및 기타사항들' 카테고리의 다른 글
| [SNS] Credly를 통한 MS Certification LinkedIn 연동 (0) | 2023.03.08 |
|---|---|
| [Cloud] Azure Data Factory 사용방법(2) (0) | 2022.07.01 |
| [Cloud] Azure Data Factory 사용방법(1) (0) | 2022.06.26 |
| [Cloud] Azure Synapse Analytics 사용방법(2) (0) | 2022.06.02 |
| [Cloud] Azure Synapse Analytics 사용방법(1) (0) | 2022.06.02 |




댓글